一种能够接受近乎无限长度文本的大模型框架
使 LLM 模型可以处理无限长文本是一项重要挑战,因为存储之前所有的 KV 会受限于内存,模型很难生成超过其训练序列长度的文本。
最近来自 MIT 高性能 AI 计算的研究者们发布了一个能够接受400万 token 的大模型结构,名叫 StreamingLLM,它只保留最新的 token 和 attention sinks,而丢弃中间的 token。这样,模型无需刷新缓存就能从最近的标记生成流畅的文本。这种方式不仅不会降低多少推理速度,而且理论上能够处理无限长度的输入。
StreamingLLM 非常适合用在模型需要持续运行而不需要大量内存或依赖过去数据的场景,例如基于 LLM 的日常助手。截止该稿撰写时,此项目已获得4.6k的 Github Star。本文将和大家一起深入了解这项工作的细节。
概述
将 LLM 应用于无限输入流时,会遇到两个主要挑战:
- 缓存冗余:在解码阶段,基于 Transformer 的 LLM 会缓存之前所有 token 的 KV,这会导致内存使用过多,增加解码延迟;
- 外推困境:现有模型的长度外推能力有限,即当序列长度超过预训练时设定的注意窗口大小时,其性能就会下降。
一种直观的方法被称为 Window Attention,其仅在最近 token 的 KV 状态上维护一个固定大小的滑动窗口。虽然这种方法能保持稳定的内存使用率和解码速度,但一旦序列长度超过缓存大小,开始对 token 的 KV 进行删除,模型的性能就会急剧下降。如下图 b 所示:
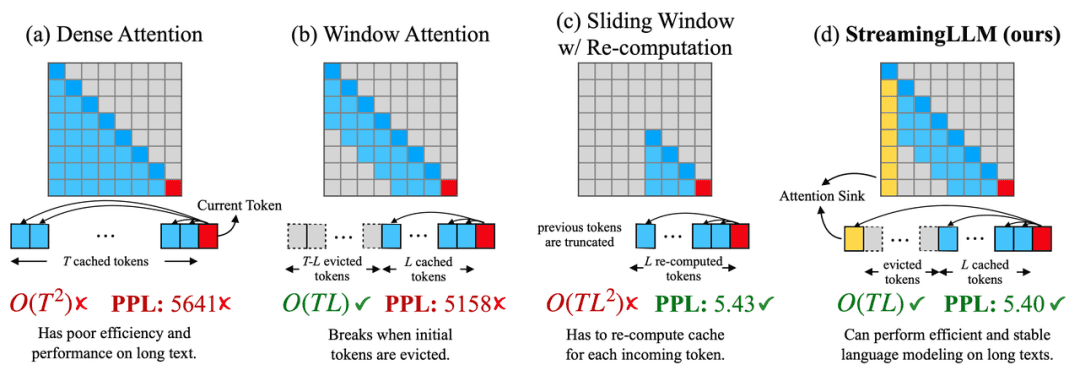
另一种策略是带重计算的滑动窗口(如上图 c 所示),这种方法会从最近的 token 中重建 KV 状态,虽然它在长文本中表现良好,但其速度明显较慢,在现实应用中并不实用。
研究者探寻 Window Attention 失效的原因,发现了自回归 LLMs 的一个有趣现象:大模型的 Attention 计算中,大量 Attention 权重被分配给某些初始 token,无论这些 token 与语言建模任务是否相关。如下图所示:
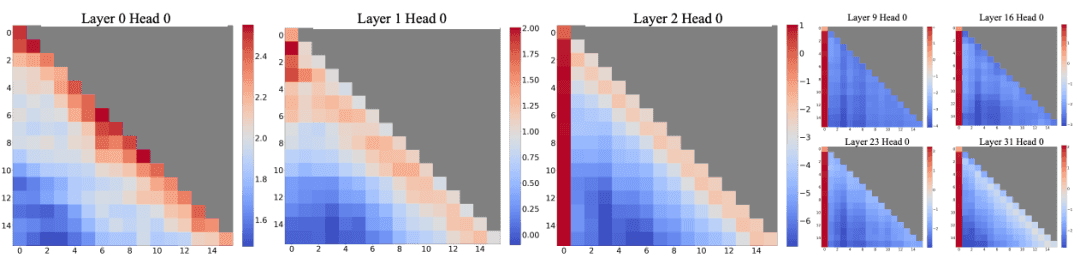
研究者们将这些 token 命名为 “attention sinks”。尽管这些初始 token 缺乏语义,但它们收集了显著的注意力分数。研究者将这个现象归因于计算中的 Softmax 操作,它要求注意力分数总和为 1 。因此当前 query 对许多先前 token 没有很强匹配的时候,仍需要在某个与语义不太相关的地方,分配这些不需要的注意力值,来使得最终分数总和为 1。初始 token 作为 sink token 的原因很直观:由于自回归语言建模的特性,初始 token 对几乎所有后续标记都是可见的,这使得它们更容易被训练成 attention sinks。
方法
借助上面的观察,研究者们提出了 StreamingLLM,一种简单而高效的框架。如图1 d 所示,该模型就是把初始 token 的 KV 保留下来,然后再拼上滑动窗口的 KV,就可以保持稳定的模型性能,因为保留 attention sinks 可以让窗口内的注意力分数分布接近正常。
1. Window Attention 失效的原因
在本节中,我们将使用 attention sinks 的概念来解释 Window Attention 失败的原因,并以此详细阐述 StreamingLLM 的灵感来源。

上图很明显可以得到,当文本长度超过缓存大小时,由于排除了初始标记,困惑度会激增。这表明,无论初始词块与被预测词块的距离如何,初始词块对于保持 LLM 的稳定性都至关重要。
图2 展示了 llama2 7b 模型的所有层和 head 的注意力图。可以发现,除了最下面两层之外,模型在所有层和 head 都始终专注于初始 token。这意味着:在注意力计算中,去掉这些初始 token 的 KV 将去掉 SoftMax 函数(公式 1)中分母的很大一部分。这种改变会导致注意力分数的分布发生显著变化,从而偏离正常推理设置中的预期。
$\operatorname{SoftMax}(x)_i=\frac{e^{x_i}}{e^{x_i}+\sum_{j=2}^N e^{x_i}}, x_1 \gg x_j, j \in 2, \ldots, N$
那么初始 token 为什么会如此重要,该论文的研究者给出了如下两种可能:
- 初始 token 的语义至关重要;
- 或者模型学习偏重于初始 token 的绝对位置
研究者用 \n 替代前四个标记符,发现模型仍然会非常重视初始换行符。这表明,初始token的绝对位置比其语义价值更加重要。
2. 具有 attention sinks 的滑动 KV 缓存
研究者提出的 StreamingLLM 是一种直接的方法,其可以在不进行任何模型微调的情况下恢复窗口注意的困惑度。除了当前的滑动窗口 token 之外,研究者还在注意力计算中重新引入了几个初始 token 的 KV。如下图所示:
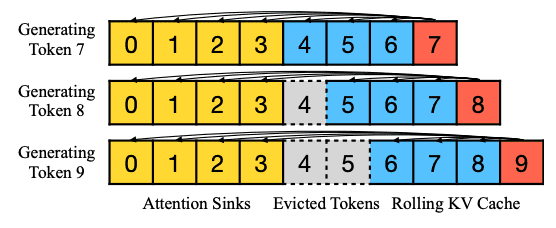
StreamingLLM 中的 KV 缓存在概念上可以分为两部分:
- attention sinks(四个initial tokens)稳定注意力计算;
- 滑动 KV 缓存保留了最新的标记,这对于语言建模至关重要。
在确定相对距离并将位置信息添加到 token 时,StreamingLLM 专注于缓存中的位置,而不是原始文本中的位置。这种区别对于 StreamingLLM 的性能至关重要。例如,如果当前缓存的 token 为 [0, 1, 2, 3, 6, 7, 8],那么在解码第 9 个令牌的过程中,分配的位置为 [0, 1, 2, 3, 4, 5, 6, 7],而不是原始文本中的位置 [0, 1, 2, 3, 6, 7, 8, 9]。
3. 带有 attention sinks 的预训练 LLMs
如1小节所述,模型过度关注多个初始 token 的一个重要原因是缺乏一个指定的 sink token 来卸载过多的注意力分数。因此,模型会无意中将全局可见的标记(主要是初始 token)指定为 attention sinks。一种可能的补救办法是有意识地加入一个可训练的全局 attention sinks 标记,称为 “Sink Token”,作为不必要注意力分数的存放处。另外,也可以用类似于 SoftMax-off-by-One 的变体来取代传统的 SoftMax 函数:
$\operatorname{SoftMax}_1(x)_i=\frac{e^{x_i}}{1+\sum_{j=1}^N e^{x_i}}$
这种 Softmax 方法不要求所有上下文 token 的注意力分数总和为 1。但要注意的是,这种替代方法等同于在注意力计算中使用 KV 特征全为零的 token 。作者将这种方法命名为 “Zero Sink”,以便与其提出的框架保持一致。
实验
研究者使用四个著名的最新模型对 StreamingLLM 进行了评估:Llama-2、MPT、PyThia 和 Falcon。研究者将 StreamingLLM 与密集注意力、窗口注意力和带重计算的滑动窗口方法等既定基准进行比较。
1. 长文本语言建模测试
研究者首先使用 PG19 测试集评估 StreamingLLM 的语言建模复杂度。如之前图3所示,在跨度为 20K token 的文本上,StreamingLLM 的困惑度可以与 Oracle 基准(滑动窗口与重新计算)相媲美。同时,当输入长度超过预训练窗口时,密集注意力技术就会失效,而当输入长度超过缓存大小时,窗口注意力技术就会陷入困境,导致初始标记被剔除。

上图进一步证实了 StreamingLLM 可以可靠地处理异常扩展的文本。在 400 多万个 token 上,四种著名的 LLM 依托 StreamingLLM 框架表现出稳定的性能,其困惑度几乎与具有重新计算基线的滑动窗口的困惑度相匹配。
2. Sink Token 的有效性
为了验证方法3中提出的 sink token 的有效性,即在所有预训练样本中引入 sink token 用于改善 StreamingLLM,研究者训练了两种语言模型,每个模型有160万个参数。在相同的条件下,一个模型采用原始训练设置上,另一个在每个训练样本的开头加入了一个 sink token。
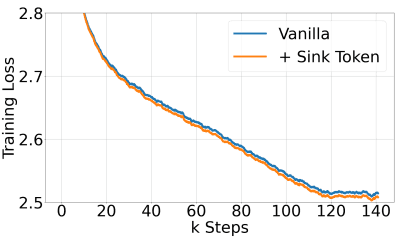
如上图所示,与普通模型相比,使用 sink token 训练的模型表现出相似的收敛动态。使用 sink token 预训练的模型与使用 vanilla 方法训练的模型的性能相似。值得注意的是,vanilla 模型需要将多个标记作为 attention sink 相加以保持稳定的困惑度。相比之下,使用 sink token 训练的模型仅使用 sink token 实现了令人满意的性能。

上图展示了使用和不使用 sink token 预训练的模型的注意力图。可以看到,没有 sink token 的模型,类似于 Llama2 7B(如图 2 所示),显示了早期层的局部注意力和更深的层关注初始标记。相比之下,使用 sink token 训练的模型始终集中在层和头部的接收器上,表明有效的注意力卸载机制。
研究者还展示了使用 StreamingLLM 进行流式 QA 的结果,还有一系列消融实验,效率实验等,感兴趣的读者可以阅读论文原文了解其细节。
总结
总的来说,该工作是一个非常典型的观察规律、分析原因、运用到实际方法的工作。其提出的 attention sink,也许像 BERT 中放在句首用于分类的 [CLS] 标记,或者是图神经网络中的 Super Node,接收的是全局或者说整个句子的信息。实际上这种方式不仅仅可以用在 LLM 上,所有 attention-based 的模型都可以参考这一方式将输入序列的长度变得更加灵活。而对于其他 AI 研究领域来说,则是很好的将解释模型与研发模型结合的例子。