一、同步控制 1. 重入锁 重入锁可以替代 synchronized 关键字,在 jdk5.0 早期,重入锁的性能好于 synchronized,从 jdk6.0 开始,synchronized 优化,两者性能差不多了。
重入锁例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class ReenterLock implements Runnable public static ReentrantLock lock = new ReentrantLock(); public static int i = 0 ; @Override public void run () for (int j = 0 ; j < 10000000 ; ++j) { lock.lock(); try { i++; } finally { lock.unlock(); } } } public static void main (String[] args) throws InterruptedException ReenterLock tl = new ReenterLock(); Thread t1 = new Thread(tl); Thread t2 = new Thread(tl); t1.start(); t2.start(); t1.join(); t2.join(); System.out.println(i); } }
非常直观地,我们发现和 synchronized 相比,这里的重入锁更加注重锁的细节 ,包括了上锁和解锁的过程。更加灵活。
值得注意的是,重入锁可以重入 。
1 2 3 4 5 6 7 8 lock.lock(); lock.lock(); try { i++; } finally { lock.unlock(); lock.unlock(); }
在这种情况下,一个线程连续两次获得同一把锁。这是允许的!如果同一个线程多次获得锁,那么在释放锁的时候,也必须释放相同次数! 如果释放锁的次数多,那么会得到一个 java. lang. IllegalMonitorState Exception 异常,反之,如果释放锁的次数少了,那么相当于线程还持有这个锁,因此,其他线程也无法进入临界区。
1.1 中断响应 对于 synchronized 来说,如果一个线程在等待锁,那么结局是获得锁 或者是保持等待 ;对于重入锁而言,还有可能被中断 。
如果一个线程正在等待锁,那么它收到一个通知,被告知无须再等待,可以停止了。
下面的代码就是一个死锁,得益于锁中断,我已解决这个死锁!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 public class IntLock implements Runnable public static ReentrantLock lock1 = new ReentrantLock(); public static ReentrantLock lock2 = new ReentrantLock(); int lock; public IntLock (int lock) this .lock = lock; } @Override public void run () try { if (lock == 1 ) { lock1.lockInterruptibly(); try { Thread.sleep(500 ); } catch (InterruptedException e) { } lock2.lockInterruptibly(); } else { lock2.lockInterruptibly(); try { Thread.sleep(500 ); } catch (InterruptedException e) { } lock1.lockInterruptibly(); } } catch (InterruptedException e) { e.printStackTrace(); } finally { if (lock1.isHeldByCurrentThread()) lock1.unlock(); if (lock2.isHeldByCurrentThread()) lock2.unlock(); System.out.println(Thread.currentThread().getId() + ":线程退出" ); } } public static void main (String[] args) throws InterruptedException IntLock r1 = new IntLock(1 ); IntLock r2 = new IntLock(2 ); Thread t1 = new Thread(r1); Thread t2 = new Thread(r2); t1.start(); t2.start(); Thread.sleep(1000 ); t2.interrupt(); } }
看到一个方法,叫做 lockInterruptiby() ,这个方法可以对中断进行响应,在等待锁的过程中,可以响应中断 。
线程 t1 获取了 lock1 ,然后去获取 lock2 ;线程 t2 获取了 lock2 ,然后去获取 lock1 。现在他们相互等待了,现在,我们中断一个线程,t2 会放弃对于 lock1 的申请,同时释放 lock2 。
所以,最后完成任务的是 t1 ,而 t2 线程放弃任务直接退出,释放资源。
1.2 锁申请等待限时 避免死锁的另外一种方法是限时等待 ,给定一个时间,让线程自动放弃。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class TimeLock implements Runnable public static ReentrantLock lock = new ReentrantLock(); @Override public void run () try { if (lock.tryLock(5 , TimeUnit.SECONDS)) { Thread.sleep(6000 ); } else { System.out.println("get lock failed" ); } } catch (InterruptedException e) { e.printStackTrace(); } finally { if (lock.isHeldByCurrentThread()) lock.unlock(); } } public static void main (String[] args) TimeLock tl = new TimeLock(); Thread t1 = new Thread(tl); Thread t2 = new Thread(tl); t1.start(); t2.start(); } }
这里的方法,是使用了 tryLock() ,第一个参数是等待时间,第二个参数是计时单位。这个例子中,用于持有锁长达 6s ,另外一个线程会申请失败。当然,这个不会导致死锁了。
tryLock() 方法也可以不需要参数。立即获取或者立即失败。同样不会死锁。
现在我们看一个非常绕的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 if (lock1.tryLock()) { try { try { Thread.sleep(500 ); } catch (InterruptedException e) { e.printStackTrace(); } if (lock2.tryLock()) { try { System.out.println(Thread.currentThread().getId() + ":My Job done" ); return ; } finally { lock2.unlock(); } } } finally { lock1.unlock(); } }
外层是一个 while 循环 ,线程1执行这里,然后线程2和它相反。如果不是 tryLock() 就非常容易死锁了,但是这里不会,因为是 tryLock() 嘛,立即返回结果,有意思的是这里的代码不能这样更改:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 try { if (lock1.tryLock()) { Thread.sleep(500 ); } try { if (lock2.tryLock()) { System.out.println(Thread.currentThread().getId() + ":My Job done" ); return ; } } finally { lock2.unlock(); } } catch (InterruptedException e) { } finally { lock1.unlock(); }
这样改将报错! 这是因为,我们假设有两个线程,线程1现在有 lock1 ,线程2现在有 lock2 ,此刻,线程1尝试获取 lock2 ,就是 try{} 代码里再用 try{} ,去获取 lock2 ,使用的是 tryLock() ,那么,现在我们失败了,于是执行到 finally{} ,问题在这里 ,我们没有 lock2 啊!所以这样改是错的。
1.3 公平锁 在大多情况下,锁都是非公平的,系统在一个锁可用的时候,从等待列表中随机挑选一个,因此不能保证其公平性。公平锁的特点是:不会产生解,只要排队,总会得到资源 。如果使用 synchronized 关键字,那么锁就是非公平的。重入锁可以设置公平性,当 fair 为 true 时,锁公平。
1 public ReentrantLock (boolean fair)
实现公平锁要维护一个有序序列 ,因此公平锁的实现成本较高,性能相对较低,默认情况下,锁是非公平的。下面的代码突出了公平锁的特点:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class FairLock implements Runnable public static ReentrantLock fairLock = new ReentrantLock(true ); @Override public void run () for (;;) { try { fairLock.lock(); System.out.println(Thread.currentThread().getName() + " 获得锁" ); } finally { fairLock.unlock(); } } } public static void main (String[] args) FairLock r1 = new FairLock(); Thread t1 = new Thread(r1, "Thread_t1" ); Thread t2 = new Thread(r1, "Thread_t2" ); t1.start(); t2.start(); } }
公平锁的情况下,t1 和 t2 将轮流获得锁,而在非公平锁的情况下,一个线程会倾向于再次获取已经持有的锁 。
重入锁的实现,主要集中在 Java 层面,包含三个要素:
原子状态。原子状态使用 CAS 操作来存储当前锁的状态,判断锁是否已经被别的线程持有。
等待队列。所有没有请求到锁的线程,会进入等待队列进行等待,待有线程释放锁后,系统就能从等待队列中唤醒一个线程,继续工作。
阻塞原语 park() 和 unpark() ,用来挂起和恢复线程。没有得到锁的线程将会被挂起。
2. Condition 条件 我们知道 wait() 和 notify() 是配合 synchronized 关键字使用的,而 Condition 是与重入锁相关联的。
主要有下面几个方法:
1 2 3 4 5 6 void await () throws InterruptedExceptionvoid awaitUninterruptibly () long awaitNanos (long nanosTimeout) throws InterruptedExceptionboolean await (long time, TimeUnit unit) throws InterruptedExceptionboolean awaitUntil (Date deadline) throws InterruptedExceptionvoid signal ()
下面是一个小例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class ReenterLockCondition implements Runnable public static ReentrantLock lock = new ReentrantLock(); public static Condition conditon = lock.newCondition(); @Override public void run () try { lock.lock(); conditon.await(); System.out.println("Thread is going on" ); } catch (InterruptedException e) { e.printStackTrace(); } finally { lock.unlock(); } } public static void main (String[] args) throws InterruptedException ReenterLockCondition tl = new ReenterLockCondition(); Thread t1 = new Thread(tl); t1.start(); Thread.sleep(2000 ); lock.lock(); conditon.signal(); lock.unlock(); } }
这里的第27行,如果我们仅仅只是唤醒了一个线程,而不放弃这个锁,那么那个线程也是没有办法继续执行的 。
在 JDK 内部,也使用了重入锁和 Condition ,比如 ArrayBlockingQueue 。
3. 信号量 信号量是锁的扩展,无论是 synchronized 和 ReentrantLock ,一次只允许一个线程访问一个资源,而信号量可以指定多个线程,同时访问一个资源。
1 2 public Semaphore (int permits) public Semaphore (int permits, boolean fair)
信号量的主要方法:
1 2 3 4 5 public void acquire () public void acquireUninterruptibly () ublic boolean tryAcquire () public boolean tryAcquire (long timeout, TimeUnit unit) public void release ()
小例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class SemapDemo implements Runnable final Semaphore semp = new Semaphore(5 ); @Override public void run () try { semp.acquire(); Thread.sleep(2000 ); System.out.println(Thread.currentThread().getId() + ": done!" ); semp.release(); } catch (InterruptedException e) { e.printStackTrace(); } } public static void main (String[] args) ExecutorService exec = Executors.newFixedThreadPool(20 ); final SemapDemo demo = new SemapDemo(); for (int i = 0 ; i < 20 ; ++i) { exec.submit(demo); } } }
上面的例子中,因为我们设置信号量为5,所以会分组完成。
4. 读写锁 ReadWriteLock 是 Jdk5 中提供的读写分离锁。假设有线程 A1、A2、A3 用来写,线程 B1、B2、B3 用来读,如果是重入锁或者内部锁那么理论上来讲:读之间、读写之间、写之间 都是串行操作。这显然是不合理的。
读写锁允许多线程同时读 ,使得 B1、B2、B3 之间真正并行。
下面有个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 public class ReadWriteLockDemo private static Lock lock = new ReentrantLock(); private static ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock(); private static Lock readLock = readWriteLock.readLock(); private static Lock writeLock = readWriteLock.writeLock(); private int value; public Object handleRead (Lock lock) throws InterruptedException try { lock.lock(); Thread.sleep(1000 ); return value; } finally { lock.unlock(); } } public void handleWrite (Lock lock, int index) throws InterruptedException try { lock.lock(); Thread.sleep(1000 ); value = index; } finally { lock.unlock(); } } public static void main (String[] args) final ReadWriteLockDemo demo = new ReadWriteLockDemo(); Runnable readRunnable = new Runnable() { @Override public void run () try { demo.handleRead(readLock); } catch (InterruptedException e) { e.printStackTrace(); } } }; Runnable writeRunnable = new Runnable() { @Override public void run () try { demo.handleWrite(writeLock, new Random().nextInt()); } catch (InterruptedException e) { e.printStackTrace(); } } }; for (int i = 0 ; i < 18 ; ++i) { new Thread(readRunnable).start(); } for (int i = 18 ; i < 20 ; ++i) { new Thread(writeRunnable).start(); } } }
如果使用读写锁,上面的代码只要2秒多,而重入锁需要进行20多秒。
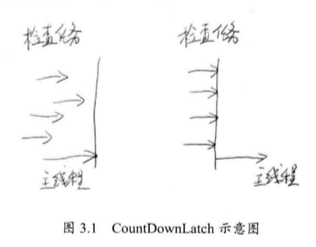
5. 倒计时器 CountDownLatch 中,CountDown 在英文中为倒计时,Latch 为门闩。
把门锁起来,不让里面的线程跑出来,因此,这个工具通常用来控制线程等待。它让一个线程等待直到倒计时结束,再开始执行 。
比如火箭发射,火箭发射前,要等待所有的检查完毕,才能点火,执行。
下面就是一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public class CountDownLoatchDemo implements Runnable static final CountDownLatch end = new CountDownLatch(10 ); static final CountDownLoatchDemo demo = new CountDownLoatchDemo(); @Override public void run () try { Thread.sleep(new Random().nextInt(10 ) * 1000 ); System.out.println("check complete" ); end.countDown(); } catch (InterruptedException e) { e.printStackTrace(); } } public static void main (String[] args) throws InterruptedException ExecutorService exec = Executors.newFixedThreadPool(10 ); for (int i = 0 ; i < 10 ; ++i) { exec.submit(demo); } end.await(); System.out.println("File!" ); exec.shutdown(); } }
上述逻辑如下:
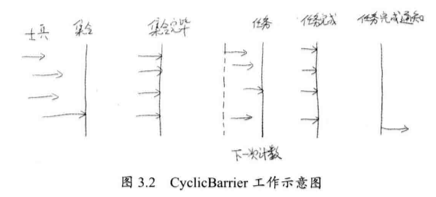
6. 循环栅栏 CyclicBarrier 是另外一个多线程并发控制工具,和 CountDownLatch 类似,它实现线程间的计数等待,但是它的功能更加复杂且强大。
前面的 Cyclic 意为循环,也就是说这个计数器可以反复使用,假如我们将计数器设置为10,那么凑齐第一批10个线程后,计数器就会归零,然后接着凑齐下一批10个线程,这就是循环栅栏内在的含义 。
比 CountDownLatch 略微强大的地方,CyclicBarrier 可以接收一个参数作为 barrierAction 。所谓的 barrierAction 就是当计数器完成一次计数后,系统会执行的动作。
下面第一个参数是等待数,第二个参数是执行的任务。
1 public CyclicBarrier (int parties, Runnable barrierAction)
比如下面的司令命令士兵的场景:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 public class CyclicBarrierDemo public static class Soldier implements Runnable private String soldier; private final CyclicBarrier cyclic; public Soldier (CyclicBarrier cyclic, String soldier) this .soldier = soldier; this .cyclic = cyclic; } @Override public void run () try { cyclic.await(); doWork(); cyclic.await(); } catch (InterruptedException e) { e.printStackTrace(); } catch (BrokenBarrierException e) { e.printStackTrace(); } } void doWork () try { Thread.sleep(Math.abs(new Random().nextInt() % 10000 )); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(soldier + ":任务完成" ); } public static class BarrierRun implements Runnable boolean flag; int N; public BarrierRun (boolean flag, int n) this .flag = flag; N = n; } @Override public void run () if (flag) { System.out.println("司令:[士兵" + N + "个,任务完成!" ); } else { System.out.println("司令:[士兵" + N + "个,集合完成!" ); flag = true ; } } } public static void main (String[] args) final int N = 10 ; Thread[] allSoldier = new Thread[N]; boolean flag = false ; CyclicBarrier cyclic = new CyclicBarrier(N, new BarrierRun(flag, N)); System.out.println("集合队伍!" ); for (int i = 0 ; i < N; ++i) { System.out.println("士兵" + i + "报道!" ); allSoldier[i] = new Thread(new Soldier(cyclic, "士兵" + i)); allSoldier[i].start(); } } } }
使用 CyclicBarrier.await() 以后每一个士兵线程集合完毕,之后再次使用该方法,将进行下一次计数,这次是监控士兵是否已经完成了任务。
这里可能有一个异常是 BrokenBarrierException ,一旦遇到这个异常,则表示当前的 CyclicBarrier 已经破损了,可能系统已经出现了问题没有办法达到线程到齐。
如果我们插入:
1 2 3 if (i == 5 ) { allSoldier[0 ].interrupt(); }
将产生1个 InterruptedException 和9个 BrokenBarrierException 。
7. LockSupport LockSupport 是一个非常方便实用的线程阻塞工具,它可以在线程内任意位置让线程阻塞。和 Thread.suspend() 相比,它弥补了由于 resume() 在前发生,导致线程无法继续执行 。它不会像 Object.wait() 相比,它不需要先获取对象的锁,也不会抛出 InterruptedException 异常。
LockSupport 的静态方法 park() 可以阻塞当前线程,类似的还有 parkNanos()、parkUntil() 等
我们重写关于 suspend() 永久挂起的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class LockSupportDemo public static Object u = new Object(); static ChangeObjectThread t1 = new ChangeObjectThread("t1" ); static ChangeObjectThread t2 = new ChangeObjectThread("t2" ); public static class ChangeObjectThread extends Thread public ChangeObjectThread (String name) super .setName(name); } @Override public void run () synchronized (u) { System.out.println("in " + getName()); LockSupport.park(); } } } public static void main (String[] args) throws InterruptedException t1.start(); Thread.sleep(100 ); t2.start(); LockSupport.unpark(t1); LockSupport.unpark(t2); t1.join(); t2.join(); } }
我们依然不能保证 unpark() 在 park() 后执行,但是可以正常结束 。只有合适因为 LockSupport 内部使用了类似信号量的机制,每为一个线程准备一个许可,如果许可可用,那么 park() 会立即返回,并消费这个许可。不可用时,会阻塞。而 unpark() 会让一个许可可用,与信号量不同的是,许可不可能超过一个,永远只有一个!
即使 unpark() 在 park() 前执行,它也可以在下一次 park() 的时候返回。
虽然 LockSupport 不会抛出 InterruptedException 异常,但是我们可以通过 Thread.interrupted() 等方法获取中断标志。
二、ThreadPool 最简单的线程创建和回收:
1 2 3 4 5 6 new Thread(new Runnable() { @Override public void run () } }).start();
上面的代码在 run() 之后自动回收该线程。对线程的使用必须掌握一个度,在有限的范围内,增加线程的数量可以明显提高系统的吞吐量 。
1. 什么是线程池 避免系统频繁创建和销毁线程,让创建的线程进行复用。好比数据库连接池。创建线程变成了从线程池获得空闲线程,关闭线程变成了向池子归还线程 。
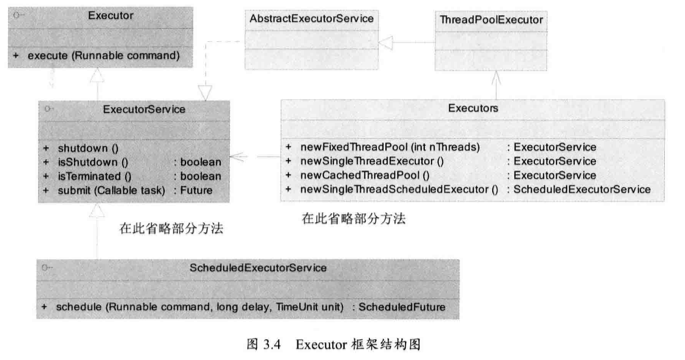
2. JDK 对线程池的支持 为了更好的控制多线程,JDK 有一套 Executor 框架,帮助开发人员有效进行线程控制,其本质就是一个线程池。
这些成员都在 java.util.concurrent 包中,是并发包的核心类。其中 ThreadPoolExecutor 表示一个线程池,Executors 类则扮演线程池工厂的角色,通过它获得一个拥有特定功能的线程池,ThreadPoolExecutor 类实现了 Executor 接口,因此通过它,任何 Runnable 对象都可以被 ThreadPoolExecutor 线程池调度。
Executor 框架提供了各种类型的线程池:
1 2 3 4 5 public static Executor Service newFixedThreadPool (int nThreads) public static ExecutorService newSingleThreadExecutor () public static ExecutorService newCachedThreadpool () public static ScheduledExecutorService newSingleThreadscheduledExecutor () public static ScheduledExecutorService newScheduledThreadPool (int corePoolsize)
下面是一个简单的例子,创建一个线程池:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class ThreadPoolDemo public static class MyTask implements Runnable @Override public void run () System.out.println(System.currentTimeMillis() + ":Thread ID:" + Thread.currentThread().getId()); try { Thread.sleep(1000 ); } catch (InterruptedException e) { e.printStackTrace(); } } } public static void main (String[] args) MyTask task = new MyTask(); ExecutorService es = Executors.newCachedThreadPool(); for (int i = 0 ; i < 10 ; ++i) { es.submit(task); } } }
之前我们一直有提到计划任务,它返回一个 ScheduledExecutorService 对象,它可以根据时间对线程进行调度,具体方法如下:
1 2 3 public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit); public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit);public ScheduledFuture<?> scheduleWithFixedDelay (Runnable command, long initialDelay, long delay, TimeUnit unit);
要知道一点,ScheduledExecutorService 并不一定会立即安排执行任务,它其实是一个计划任务的作用,会在指定时间,进行调度 。
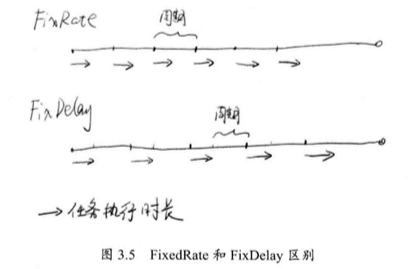
关于 scheduleAtFixedTime() 和 scheduleWithFixedDelay() 的区别如下:
对于 rate 而言,任务的频率是一定的,上一次任务开始到下一次任务开始,经过了一个周期时间;对于 delay 而言,上一次任务结束,经过 delay 时间后,再开始下一次的任务 。
下面是一个关于 scheduleAtFixedRate() 方法的调用例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class ScheduledExecutorServiceDemo public static void main (String[] args) ScheduledExecutorService ses = Executors.newScheduledThreadPool(10 ); ses.scheduleAtFixedRate(new Runnable() { @Override public void run () try { Thread.sleep(1000 ); System.out.println(System.currentTimeMillis() / 1000 ); } catch (InterruptedException e) { e.printStackTrace(); } } }, 0 , 2 , TimeUnit.SECONDS); } }
任务周期是 2S ,任务的实际执行是 1S ,两秒调用一次。
如果任务执行的时间超过周期,那么周期被拉长到任务执行的长度 。
任务如果中断,那么不会永久执行!要好好做异常处理。
3. 核心线程池的实现 那么对于核心的几个线程池,使用了 newFixedThreadPool() 方法,newSingleThreadExecutor() 方法还有 newCachedThreadPool() 方法,虽然看起来创建的线程有着完全不同的特点,但是内部均使用 ThreadPoolExecutor 实现 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public static ExecutorService newFixedThreadPool (int nThreads) return new ThreadPoolExecutor(nThreads, nThreads OL, TimeUnit.MILLISECONDS new LinkedBlockingQueue <Runnable>()); } public static ExecutorService newSingleThreadExecutor () return new FinalizableDelegatedExecutor Service (new ThreadPoolExecutor(1 , 1 , OL, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); } public static ExecutorService newCachedThreadPool () return new ThreadPoolExecutor(0 , Integer.MAXVALUE, 60L , TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
我们来看看 ThreadPoolExecutor 类的封装吧:
1 2 3 4 5 6 7 public ThreadPoolExecutor (int corePoolsize, // 线程池中线程数量 int maximumPoolSize, // 线程池中最大的线程数量 long keepAliveTime, // 当超过 corePoolSize 时,多余线程的存活时间 TimeUnit unit, // keepAliveTime 的单位 BlockingQueue<Runnable> workQueue, // 被提交但仍未执行的任务 ThreadFactory threadFactory, // 线程工厂,用于创建线程 RejectedExecutionHandler handler // 拒绝策略)
其中值得注意的 workQueue ,是一个 BlockingQueue 接口的对象,仅仅用于存放 Runnable 对象,在 ThreadPoolExecutor 的构造函数中有以下几种 BlockingQueue :
直接提交队列 :该功能由 SynchronousQueue 对象提供,这是一个特殊的 BlockingQueue 。它没有容量,每一个插入操作都要等待一个相应的删除操作,反之,每一个删除都要等待一个插入操作。
任务提交到 SynchronousQueue 不会被真实保存,而是将新任务提交给线程执行,如果没有空闲进程,则尝试创建新的进程,如果进行数量已经最大,则执行拒绝策略 。因此使用 SynchronousQueue 队列,通常要设置 maximumPoolSize 值。
有界任务队列 :通过 ArrayBlockingQueue 实现,有新任务时,如果任务数量小于 corePoolSize ,则优先创建新的线程,若大于 corePoolSize ,则将任务加入等待队列,若队列已满,则在总数不大于 maximumPoolSize 的情况下,创建新的线程执行任务,若大于 maximumPoolSize ,则执行拒绝策略。
有界队列在队列装满时,才可能将线程数提升到 corePoolSize 以上,除非系统繁忙,否则将确保线程数维持在 corePoolSize 。
无界任务队列 :无界任务队列通过 LinkedBlockingQueue 类实现,当有新的任务到来,系统线程数小于 corePoolSize 时,会生成新的线程执行任务,但达到 corePoolSize 后,不会继续增加了。若还有任务,而没有空闲线程,则进入队列等待,直到耗尽系统内存。优先任务队列 :通过 PriorityBlockingQueue 实现,它是特殊的无界队列,之前的有界和无界队列都是按照先进先出算法处理任务的,而 PriorityBlockingQueue 则可以通过任务自身的优先级顺序先后执行(确保高优先级任务先执行)。
使用 newFixedThreadPool() 方法将返回一个 corePoolSize 和 maximumPoolSize 大小一样的使用无界任务队列 的线程池。使用的是 LinkedBlockingQueue 任务队列。使用这个任务队列存放无法立即执行的任务。
使用 newCachedThreadPool() 方法将返回 corePoolSize 为 0 ,maximumPoolSize 无穷大的线程池,没有任务时,线程池中没有现成,当任务被提交,线程池将使用空闲的线程执行任务,若无空闲线程,则将任务加入 SynchronounsQueue 队列,直接提交队列,它迫使线程池增加新的线程执行任务,当任务完毕,由于 corePoolSize 为 0 ,因此空闲线程会在指定时间内被回收。
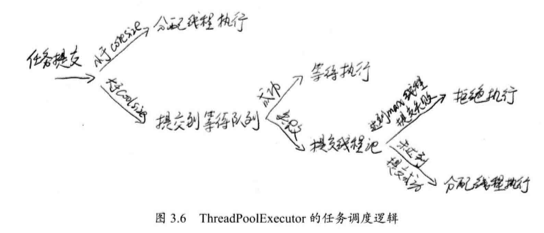
下面是 ThreadPoolExecutor 线程池的核心调度逻辑:
4. 拒绝策略 JDK 内置如下拒绝策略:
AbortPolicy 策略:该策略会直接抛出异常,阻止系统正常工作。
CallerRunsPolicy 策略:只要线程池未关闭,该策略直接在调用者线程中,运行当前被丢弃的任务。显然这样做不会真的丢弃任务,但是,任务提交线程的性能极有可能会急剧下降。
DiscardOldestPolicy 策略:该策略将丢弃最老的一个请求,也就是即将被执行的一个任务,并尝试再次提交当前任务。
DiscardPolicy 策略:该策略默默地丢弃无法处理的任务,不予仼何处理。如果允许任务丢失,我觉得这可能是最好的一种方案了吧!
这些策略都实现了 RejectedExecutionHandler 接口,我们可以自己扩展这个接口,该接口定义如下:
1 2 3 public interface RejectedExecutionHandler void rejectedExecution (Runnable r, ThreadPoolExecutor executor) }
下面的代码执行需要 100 毫秒,因此有大量任务被直接丢弃:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class RejectThreadPoolDemo public static class MyTask implements Runnable @Override public void run () System.out.println(System.currentTimeMillis() + ":Thread ID:" + Thread.currentThread().getId()); try { Thread.sleep(100 ); } catch (InterruptedException e) { e.printStackTrace(); } } } public static void main (String[] args) throws InterruptedException MyTask task = new MyTask(); ExecutorService es = new ThreadPoolExecutor(5 , 5 , 0L , TimeUnit.MILLISECONDS, new LinkedBlockingDeque<>(10 ), new RejectedExecutionHandler() { @Override public void rejectedExecution (Runnable r, ThreadPoolExecutor executor) System.out.println(r.toString() + " is discard" ); } }); for (int i = 0 ; i < Integer.MAX_VALUE; ++i) { es.submit(task); Thread.sleep(10 ); } } }
5. 自定义线程创建 我们开始思考一个问题:线程池里的线程是哪里来的?最开始的时候,线程通过 ThreadFactory 创建。ThreadFactory 是一个接口,它只有一个方法,用来创建线程:
1 Thread newThread (Runnable r) ;
下面的案例使用自定义的 ThreadFactory ,一方面记录了线程的创建,另一方面将所有线程设置为守护线程,这样主线程退出的时候,会强制销毁线程池。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public class FactoryDemo public static class MyTask implements Runnable @Override public void run () System.out.println(System.currentTimeMillis() + ":Thread ID:" + Thread.currentThread().getId()); try { Thread.sleep(100 ); } catch (InterruptedException e) { e.printStackTrace(); } } } public static void main (String[] args) throws InterruptedException MyTask task = new MyTask(); ExecutorService es = new ThreadPoolExecutor(5 , 5 , 0L , TimeUnit.MILLISECONDS, new SynchronousQueue<>(), new ThreadFactory() { @Override public Thread newThread (Runnable r) Thread t = new Thread(r); t.setDaemon(true ); System.out.println("create " + t); return t; } }); for (int i = 0 ; i < 5 ; ++i) { es.submit(task); } Thread.sleep(2000 ); } }
6. 扩展线程池 虽然线程池已经有了,但是我们需要对它扩展,比如任务开始、结束的时间,或者其他一些功能。ThreadPoolExecutor 是一个可以扩展的线程池,有 beforeExecute() 、 afterExecute() 、 terminated() 三个接口对线程池进行控制。
在 ThreadPoolExecutor.Worker.runTask() 方法内部有这样的实现:
1 2 3 4 5 6 7 8 9 10 11 boolean ran = false ;beforeExecute(thread, task); try { task.run(); ran = true ; afterExecute(task, null ); ++completedTasks; } catch (RuntimeException ex) { if (!ran) afterExecute(task, ex); throw ex; }
这里的 Worker 是 ThreadPoolExecutor 的内部类,实现了 Runnable 接口。ThreadPoolExecutor 线程池中的线程正是 Worker 实例。Worker.runTask() 方法会被线程池以多线程模式异步调用,就是说这个方法会同时被多个线程访问,因此这里的 beforeExecute() 和 afterExecute() 接口也将同时被多线程访问。
默认下,这两个方法是空的,我们可以对其扩展,对线程池运行状态跟踪,输出有用的调试信息,下面是一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 public class ExtThreadPool public static class MyTask implements Runnable public String name; public MyTask (String name) this .name = name; } @Override public void run () System.out.println("正在执行:Thread ID:" + Thread.currentThread().getId() + ", Task name = " + name); try { Thread.sleep(100 ); } catch (InterruptedException e) { e.printStackTrace(); } } } public static void main (String[] args) throws InterruptedException ExecutorService es = new ThreadPoolExecutor(5 , 5 , 0L , TimeUnit.MILLISECONDS, new LinkedBlockingDeque<Runnable>()) { @Override protected void beforeExecute (Thread t, Runnable r) System.out.println("准备执行:" + ((MyTask) r).name); } @Override protected void afterExecute (Runnable r, Throwable t) System.out.println("执行完成:" + ((MyTask) r).name); } @Override protected void terminated () System.out.println("线程池退出" ); } }; for (int i = 0 ; i < 5 ; ++i) { MyTask task = new MyTask("Task-" + i); es.execute(task); Thread.sleep(10 ); } es.shutdown(); } }
有意思的是这里使用的是 execute() 而不是 submit() 。
execute(Runnable x) 没有返回值。可以执行任务,但无法判断任务是否成功完成。(异步执行)submit(Runnable task) 返回一个 Future 。通过 get 等待直到获取到检索结果为止。(同步执行)
7. 优化线程池线程的数量 在 《Java Concurrency in Practice》 选中有一个估算线程池带下的公式:
最优的池的大小:
在 Java 中,我么可以通过如下方法获取可用 CPU 数量:
1 Runtime.getRuntime().availableProcessors()
8. 在线程池中寻找堆栈 计算两个数的商:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class DivTask implements Runnable int a, b; public DivTask (int a, int b) this .a = a; this .b = b; } @Override public void run () double re = a / b; System.out.println(re); } public static void main (String[] args) ThreadPoolExecutor pools = new ThreadPoolExecutor(0 , Integer.MAX_VALUE, 0L , TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); for (int i = 0 ; i < 5 ; ++i) { pools.submit(new DivTask(100 , i)); } } }
上面的代码只有4个输出,当除数 i 为0,结果没有计算,一个简单的方法是放弃 submit() ,使用 execute() 。
这里我们可以得到一些错误信息:
1 2 3 Exception in thread "pool-1-thread-1" java.lang.ArithmeticException: / by zero at threadPool.DivTask.run(DivTask.java:19) ...
我们还想要一个重要信息,就是任务在哪里提交的?与其以后加班,不如扩展 ThreadPoolExecutor 线程池,让它在调度任务之前,先保存一下提交任务线程的堆栈信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 public class TraceThreadPoolExecutor extends ThreadPoolExecutor public TraceThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) super (corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue); } @Override public void execute (Runnable command) super .execute(wrap(command, clientTrace(), Thread.currentThread().getName())); } @Override public Future<?> submit(Runnable task) { return super .submit(wrap(task, clientTrace(), Thread.currentThread().getName())); } private Exception clientTrace () return new Exception("Client stack trace" ); } private Runnable wrap (final Runnable task, final Exception clientStack, String clientThreadName) return new Runnable() { @Override public void run () try { task.run(); } catch (Exception e) { clientStack.printStackTrace(); throw e; } } }; } public static void main (String[] args) ThreadPoolExecutor pools = new TraceThreadPoolExecutor(0 , Integer.MAX_VALUE, 0L , TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); for (int i = 0 ; i < 5 ; ++i) { pools.execute(new DivTask(100 , i)); } } }
现在代码报错还将显示以下信息:
1 2 3 4 java.lang.Exception: Client stack trace at threadPool.TraceThreadPoolExecutor.clientTrace(TraceThreadPoolExecutor.java:22) at threadPool.TraceThreadPoolExecutor.execute(TraceThreadPoolExecutor.java:13) at threadPool.TraceThreadPoolExecutor.main(TraceThreadPoolExecutor.java:43)
我们现在找到了任务提交的地方。
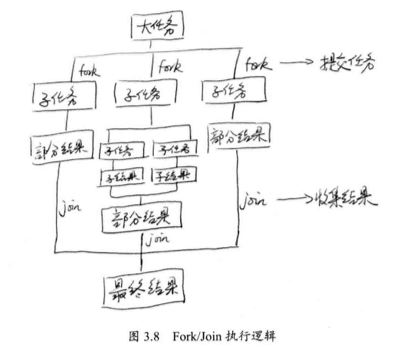
9. Fork/Join 框架 分而治之是非常有效处理大量数据的方法,著名的 MapReduce 也是采用了分而治之的思想,在 Linux 平台,函数 fork() 用来创建子进程,使得系统进程可以多一个执行分支,在 Java 中类似,而 join() 的意思是等待,使用了 fork() 以后多了一个执行分支,所以需要等待。
在 JDK 中,有一个 ForkJoinPool 线程池,对于 fork() 方法并不急着开启的,而是交给 ForkJoinPool 线程池进行处理。
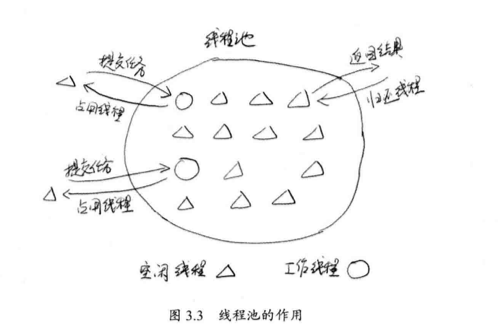
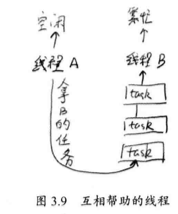
大多数情况下一个物理线程需要处理多个逻辑任务,每个线程需要一个任务队列 ,可能存在:线程 A 已经将任务完成,而 B 还有任务要处理,线程 A 将帮助线程 B ,达到平衡,这是一种互助,如下图所示。
当线程帮助别人的时候,总是从底部开始拿数据,这样避免了数据的竞争。
下面是一个 ForkJoinPool 的重要接口:
1 public <T> ForkJoinTask<T> submit (ForkJoinTask<T> task)
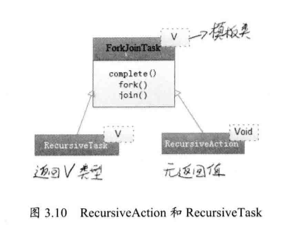
我们可以向 ForkJoinPool 线程池提交一个 ForkJoinTask 任务,这样的任务就是支持 fork() 和 join() 的任务,而它有两个重要的子类,RecursiveAction 和 RecursiveTask ,他们分别表示没有返回值的任务和可以携带返回值的任务。
下面是一个小例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 public class CountTask extends RecursiveTask <Long > private static final int THRESHOLD = 10000 ; private long start; private long end; public CountTask (long start, long end) this .start = start; this .end = end; } @Override protected Long compute () long sum = 0 ; boolean canCompute = (end - start) < THRESHOLD; if (canCompute) { for (long i = start; i <= end; ++i) { sum += i; } } else { long step = (start + end) / 100 ; ArrayList<CountTask> subTasks = new ArrayList<>(); long pos = start; for (int i = 0 ; i < 100 ; ++i) { long lastOne = pos + step; if (lastOne > end) lastOne = end; CountTask subTask = new CountTask(pos, lastOne); pos += step + 1 ; subTasks.add(subTask); subTask.fork(); } for (CountTask t : subTasks) { sum += t.join(); } } return sum; } public static void main (String[] args) ForkJoinPool forkJoinPool = new ForkJoinPool(); CountTask task = new CountTask(0 , 200000L ); ForkJoinTask<Long> result = forkJoinPool.submit(task); try { long res = result.get(); System.out.println("sum + " + res); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } } }
ForkJoin 线程池使用一个无锁的栈来管理空闲的线程,如果工作线程暂时取不到可用的任务,则可能挂起,挂起线程被压入由线程池维护的栈中,待将来有任务时,再唤醒这些线程。
三、JDK 的并发容器 1. 并发集合 JDK 提供的这些容器大部分在 java.util.concurrent 包中,这些容器主要如下:
ConcurrentHashMap:这是一个高效的并发 HashMap 。你可以理解为一个线程安全的 HashMap 。
CopyOnWriteArrayList:这是一个 List ,从名字看就是和 ArrayList 是一族的。在读多写少 的场合,这个 List 的性能非常好,远远好于 Vector 。
ConcurrentLinkedQueue:高效的并发队列,使用链表实现。可以看做一个线程安全的 Linkedlist 。
BlockingQueue:这是一个接口,JDK 内部通过链表、数组等方式实现了这个接口。表示阻塞队列,非常适合用于作为数据共享的通道。
ConcurrentSkipListMap:跳表的实现。这是一个 Map ,使用跳表的数据结构进行快速查找。
此外,Vector 也是线程安全,但是性能和上述专用工具没得比,另外 Collections 工具类可以帮助我们将任意集合包装成线程安全的集合。
2. 线程安全的 HashMap 做到线程安全的 HashMap ,一种可行的是 Colletions.synchronizedMap() 方法包装我们的 HashMap ,下面的 HashMap 就是线程安全的:
1 public static Map m = Collections.synchronizedMap(new HashMap());
Collections.synchronizedMap() 会生成一个名为 SynchronizedMap 的 Map 。它使用了委托,将自己所有 Map 相关的功能交给传入的 HashMap 实现,而自己则负责保证线程安全。
首先,我们用 SynchronizedMap 包装一个 Map :
1 2 3 4 5 private static class SynchronizedMap <K , V > implements Map <K , V > Serializable private static final long serialVersionUID = 197 ...L; private final Map<K, V> m; final Object mutex; }
这里我们通过 mutex 实现对这个 m 的互斥操作。比如,对于 Map.get() 方法,实现如下:
1 2 3 4 5 public V get (Object key) synchronized (mutex) { return m.get(key) } }
其他相关的 Map 操作都会使用这个 mutex 进行同步,从而实现线程安全。
如果并发级别不高,一般够用,但是在高并发下我们需要新的解决方案,一个更加专业的并发 HashMap 是 ConcurrentHashMap ,它专门为并发进行性能优化。
3. 有关 List 的线程安全 在 Java 中 ArrayList 和 Vector 都是使用数组作为实现,前者非线程安全,后者为线程安全,我们也可以使用 Collections 包来完成 ArrayList 的线程安全:
1 public static List<String> list = Collections.synchronizedList(new LinkedList<String>());
4. 高效读写队列 ConcurrentLinkedQueue ConcurrentLinkedQueue 应该算在高并发环境中性能最好的队列。
首先在 ConcurrentLinkedQueue 中,定义了节点 Node :
1 2 3 4 private static class Node <E > volatile E item; volatile Node<E> next; }
使用 CAS 操作对 Node 进行一些维护:
1 2 3 boolean casItem (E cmp, E val) return UNSAFE.compareAndSwapObject(this , itemOffset, cmp, val); }
它内部有两个字段,head 和 tail ,分别代表链表头和链表尾,我们可以通过 head 以及 succ() 方法来遍历,而 tail 表示队列的末尾。
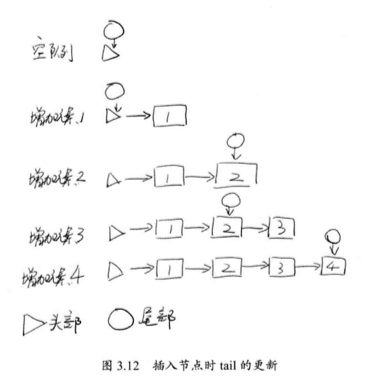
一般,我们期望 tail 总是末尾,但是实际上更新不是及时的,存在拖延现象,如下所示:
tail 的更新会延后,每次跳跃两个元素。
我们看一下加入节点的方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public boolean offer (E e) checkNotNull(e); final Node<E> newNode = new Node<E>(e); for (Node<E> t = tail, p = t;;) { Node<E> q = p.next; if (q == null ) { if (p.casNext(null , newNode)) { if (p != t) casTail(t, newNode); return true ; } } else if (p == q) p = (t != (t = tail)) ? t : head; else p = (p != t && t != (t = tail)) ? t : q; } }
初始情况下,由于队列为空,所以 p.next 为 null ,然后将 p 的 next 节点赋值 newNode ,也就是将新的元素加入到队列中,此时 p == t 是成立的,因此不会更新结尾 tail ,因此增加一个元素后,tail 并不会更新。
当我们试图增加第二个元素时,由于 t 在 head 的位置,因此 p.next 指向第一个元素,现在 q != null ,q 不是最后的节点。于是代码开始寻找最后一个节点。此时, p 指向第一个元素,而它的 next 是 null ,p 更新自己的 next ,此时 p != t ,于是更新 t 所在的位置,到链表的最后。
那么什么时候会出现 p == q 呢?这是因为遇到了哨兵节点,就是 next 指向自己的节点。主要表示要删除的节点和空节点。出现了的话,则使用新的 tail 作为结尾,避免重新查找 tail 的开销。
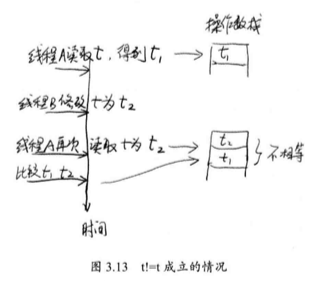
在单线程下,这就话不容易理解:
1 p = (t != (t = tail)) ? t : head;
!= 不是原子操作,首先是 t 的值,然后执行 t = tail ,取得新的 t 的值,然后比较是否相等,单线程不会出现 t != t ,但是在并发下,右边可能修改了,如果修改了,就现在进行修改,如果没有修改,重新查找结尾。
哨兵是怎么产生的呢?
1 2 3 ConcurrentLinkedQueue<String> q = new ConcurrentLinkedQueue<String>(); q.add("1" ); q.poll();
下面是 poll() 方法的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public E poll () restartFromHead: for (;;) { for (Node<E> h = head, p = h, q;;) { E item = p.item; if (item != null && p.casItem(item, null )) { if (p != h) updateHead(h, ((q = p.next) != null ) ? q : p); return item; } else if ((q = p.next) == null ) { updateHead(h, p); return null ; } else if (p == q) continue restartFromHead; else p = q; } } }
由于现在队列中只有一个元素,所以 tail 没有更新,而是指向和 head 相同的位置,此时 head 本身的 item 是空的,next 是第一个元素,首先我们代码到 p = q 的位置,p 现在指向了第一个元素,第二次循环,p 的 item 被设置成了 null ,也就是弹出元素,被删除,此时 p 和 h 当然不等了,故执行了 updateHead() 方法:
1 2 3 4 final void updateHead (Node<E> h, Node<E> p) if (h != p && casHead(h, p)) h.lazySetNext(h); }
将 p 设置为链表的表头,原来的 head 被设置成了哨兵,通过 lazySetNext() 实现。现在一个哨兵节点被创建了,原来的 head 和 tail 实际上就是一个元素,如果再次执行 offer() 将会遇到这个 tail 。
原来头节点没用了,next指向本身,变成哨兵节点。
5. 不变模式下的 CopyOnWriteArrayList 有些场景下,读远远大于写,我们希望读尽可能快,写慢一点点没关系。
我们应该允许多个线程访问,但是写应该受到阻碍。所谓 CopyOnWrite 就是在写的时候,进行一次自我复制,如果需要修改,我们并不修改原有的内容 ,写完之后再替换,不影响读操作。
1 2 3 4 5 6 7 8 9 10 private volatile transient Object[] array;public E get (int index) return get(getArray(), index); } final Object[] getArray() { return array; } private E get (Object[] a, int index) return (E) a[index]; }
和读取相比,写入就比较麻烦了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public boolean add (E e) final ReentrantLock lock = this .lock; lock.lock(); try { Object[] elements = getArray(); int len = elements.length; Object[] newElements = Arrays.copyOf(elements, len + 1 ); newElements[len] = e; setArray(newElements); return true ; } finally { lock.unlock(); } }
这里为什么需要使用 final ReentrantLock lock = this.lock; 这句话,一部分重要一部分不重要。
重要:
this.lock 是类的成员变量,一般都是存到堆上,访问堆上的变量会涉及内存同步的操作(这个建议通过编译后的 bytecode 进行观察),而将其 copy 到栈上,然后访问就不存在这个问题了。
在访问堆上的 this.lock 时,对于多个 CPU ,可能会存在 cache 命中的问题,这样必然会导致内存重新 load ,而 copy 到栈上,则直接是线程相关的,就不存在这个问题了。
不重要:
这个 final 对于编译而言是可有可无的,即便将其final修饰符去掉,效果也一样。
Jdk1.6 及以前是没有这句话的,对结果是没有影响的。
首先使用锁,生成一个新的数组,然后将元素加入,接着新数组替换老数组,不影响读,修改完成,读就察觉了,因为 array 是 volatile 类型的。
6. 数据共享通道 我们说过 ConcurrentLinkedQueue 可以作为高性能的队列,但多线程的开发还有一个问题,如何在多个线程之间进行数据共享呢?
一般来说,我们总是希望系统是松耦合的。
如果我们进行重构或者升级,可以不修改线程 A ,而直接把线程 B 升级成线程 C ,保证系统的平滑过渡,其中升级的意见箱使用 BlockingQueue 来实现。
与之前的 ConcurrentLinkedQueue 和 CopyOnWriteArrayList 不同,BlockingQueue 是一个接口,而不是一个实现,主要实现有下面的内容:
其中 ArrayBlockingQueue 是基于数组实现的,而 LinkedBlockingQueue 基于链表。正因为如此 ArrayBlockingQueue 更适合做有界队列,因为队列中可以容纳的最大元素在创建的时候指定;而 LinkedBlockingQueue 适合做无界队列,内部元素可以动态增加。
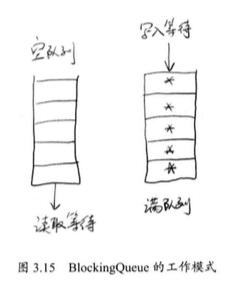
BlockingQueue 之所以适合作为数据共享的通道,关键在于 Blocking 上,它有阻塞的意思,当服务线程处理完队列中信息后,如何知道下一条信息何时到来?
它会让服务线程在队列为空的时候,进行等待,当有信息进入队列后,自动将线程唤醒。
ArrayBlockingQueue 内部有一个对象数组:
向队列中压入元素使用 offer() 方法和 put() 方法,对于 offer ,如果队列满了,返回 false ,如果没有满,则正常入队列。对于 put ,是压入队列的末尾,如果队列满了,会一直等待,直到队列中有空闲的位置。
从队列中弹出元素可以使用 poll() 方法和 take() 方法,他们都是从头部获取一个元素,不同在于,队列如果为空 poll 方法会直接返回 null ,而 take 会等待,直到队列内有元素。
为了做好等待和通知两件事,在 ArrayBlockingQueue 内部定义了以下一些字段:
1 2 3 final ReentrantLock lock;private final Condition notEmpty;private final Condition notFull;
当执行 take() 操作时,如果队列为空,则让当前线程等待在 notEmpty 上,新元素加入,则进行一次 notEmpty 上的通知。
下面是 take 的过程:
1 2 3 4 5 6 7 8 9 10 11 public E take () throws InterruptedException final ReentrantLock lock = this .lock; lock.lockInterruptibly(); try { while (count == 0 ) notEmpty.await(); return extract(); } finally { lock.unlock(); } }
代码会循环进行等待,当有新元素进入,线程会得到通知,下面是加入元素的代码。
1 2 3 4 5 6 private void insert (E x) items[putIndex] = x; putIndex = inc(putIndex); ++count; notEmpty.signal(); }
当新元素进入队列,需要通知在 notEmpty 上的线程,让他们继续工作。
同理,对于 put 操作,当队列满的时候,需要让压入线程等待:
1 2 3 4 5 6 7 8 9 10 11 12 public void put (E e) throws InterruptedException checkNotNull(e); final Reentrantlock lock = this .lock; lock.lockInterruptibly(); try { while (count == items.length) notFull.await(); insert(e); } finally { lock.unlock(); } }
当有元素挪走,出现了空位,自然也需要通知入队的线程:
1 2 3 4 5 6 7 8 9 private E extract () final Object[] items = this .items; E x = items[takeIndex]; items[takeIndex] = null ; takeIndex = inc(takeIndex); --count; notFull.signal(); return x; }
在生产者消费者中还会有 BlockingQueue 的身影。
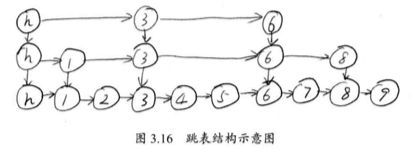
7. 跳表 跳表有点类似平衡树,平衡树的插入和删除往往可能导致平衡树进行一次全局的调整。而跳表的插入和删除只需要对整个数据结构的局部进行操作即可。在高并发下,我们需要一个全局锁来保证整个平衡树的线程安全;对于跳表,我们只需要部分锁即可。
查询而言,跳表的复杂度也是 O(log n) ,JDK 使用跳表来实现一个 Map 。
跳表的另外一个特点是随机算法,它的本质是维护了多个链表,而且链表是分层的:
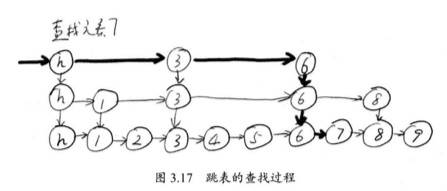
每上面一层链表都是下面的子集,一个元素插入哪些层是完全随机的。查找时,我们从顶层链表开始找,一旦发现查找元素大于当前链表的取值,跳到下一层继续。
到第二层,我们找到 8 ,但是 8 比 7 大,不行,继续进入下一层,这样查找,比从元素 1 开始逐个查找要快得多。
和哈希算法不同在于:哈希不会保存元素的顺序,而跳表的元素是排序的。
实现这一数据结构的类是 ConcurrentSkipListMap 。下面是一个跳表的简单使用:
1 2 3 4 5 6 7 Map<Integer, Integer> map=new ConcurrentskipListMap<Integer, Integer>(); for (int i=0 ;i<30 ;i++){ map. put(, i); } for (Map.Entry<Integer, Integer> entry:map.entrySet()) { System.out.println(entry.getKey()); }
和 HashMap 不同,跳表的输出是有序的。
跳表的内部实现有几个关键的数据结构组成。首先是 Node ,一个 Node 就是一个节点,里面含有两个重要的元素 key 和 value 。每个 Node 还会指向下一个 Node ,因此还有一个元素 next 。
1 2 3 4 5 static final class Node <K ,V > final K key; volatile Object value; volatile Node<K,V> next; }
对 Node 的所有操作,使用的是 CAS 方法:
1 2 3 4 5 6 7 boolean casValue (Object cmp, Object val) return UNSAFE.compareAndSwapObject(this , valueOffset, cmp, val); } boolean casNext (Node<K,V> cmp, Node<K,V> val) return UNSAFE.compareAndSwapObject(this , nextOffset, cmp, val); }
另外一个数据结构是 Index ,表示索引,内部包装了 Node ,同时增加了向下的引用和向右的引用。
1 2 3 4 5 static class Index <K ,V > final Node<K,V> node; final Index<K,V> down; volatile Index<K,V> right; }
整个跳表就是根据 Index 进行全网的组织的。
此外,对于每一层的表头,还需要记录当前在哪一层,为此,还需要一个称为 HeadIndex 的数据结构,表示链表头部的第一个 Index ,它集成自 Index 。
1 2 3 4 5 6 7 static final class HeadIndex <K , v > extends Index <K , v > final int level; HeadIndex(Node<K, V> node, Index<K, V> down, Index<K, v> right, int level) { super (node, down, right); this .level = level; } }
对于跳表的所有操作,就是组织好这些 Index 之间的连接关系。