public Matcher matcher(CharSequence input){ if (!compiled) { synchronized(this) { if (!compiled) { compile(); } } } Matcher m = new Matcher(this, input); return m; }
对于『HashMap』而言,最重要的自然是 get 方法和 put 方法,我们如果全局加锁,那么锁的粒度太大,在『ConcurrentHashMap』中,将细分若干小的『HashMap』,这些被称作段,默认下一个『ConcurrentHashMap』被分为16个段。
如果现在往『ConcurrentHashMap』中添加元素,不是将整个『HashMap』加锁,而是根据「hashcode」决定将该项放到哪个段中,然后对段进行加锁,如果多线程执行 put 方法,只要不是同一个段,那么就是真正的并行!
因为默认是16个段,如果够幸运,应该最多能同时接受16个线程,大大提高了吞吐量。下面是 put 方法的源码:
1 2 3 4 5 6 7 8 9 10
public V put(K key, V value){ Segment<K,V> s; if (value == null) thrownew NullPointerException(); int hash = hash(key); // 获取 key 相应的 hash int j = (hash >>> segmentShift) & segmentMask; // 获取段序号 if ((s = (Segment<K, V>)UNSAFE.getObject(segments, (j << SSHIFT)+ SBASE)) == null) // recheck s = ensureSegment(j); // 得到段 return s.put(key, hash, value, false); }
减少锁粒度将引发一个新的问题:当系统获取全局锁的时候,消耗的内存比较多。
虽然我们的 put 方法很好的分离了锁,但是当我们试图访问『ConcurrentHashMap 的全局信息的时候,需要同时取得所有锁才能顺利实施,比如说 size 方法,它的实现如下:
1 2 3 4 5 6 7
sum = 0; for (int i = 0; i < segments.length; ++i) // 对所有的段加锁 segments[i].lock(); for (int i = 0; i < segments.length; ++i) // 统计总数 sum += segments[i].count; for (int i = 0; i < segments.length; ++i) // 释放所有锁 segments[i].unlock();
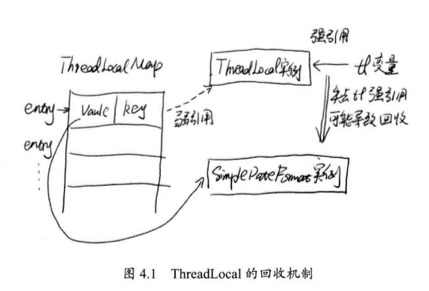
我们在设置『ThreadLocal』的数据,就是写入这个「map」中,其中「key」是当前对象,而「value」是我们需要的值,那么 get 就是从「map」中取出数据:
1 2 3 4 5 6 7 8 9 10 11
public T get(){ Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) { ThreadLocalMap.Entry e = map.getEntry(this); if (e != null) { return (T)e.value; } } return setInitialValue(); }
首先 get 获得当前线程的『ThreadLocalMap』对象,然后通过自己作为「key」获得内部实际数据。
public Random getRandom(){ if (mode == 0) { return rnd; } elseif (mode == 1) { return tRnd.get(); } else { returnnull; } }
@Override public Long call(){ long b = System.currentTimeMillis(); for (long i = 0; i < GEN_COUNT; i++) { getRandom().nextInt(); } long e = System.currentTimeMillis(); System.out.println(Thread.currentThread().getName() + "spend " + (e - b) + "ms"); return e - b; } }
publicstaticvoidmain(String[] args)throws ExecutionException, InterruptedException { Future<Long>[] futs = new Future[THREAD_COUNT]; for (int i = 0; i < THREAD_COUNT; ++i) { futs[i] = exe.submit(new RndTask(0)); } long totaltime = 0; for (int i = 0; i < THREAD_COUNT; ++i) { totaltime += futs[i].get(); } System.out.println("多线程访问同一个 Random 实例:" + totaltime + "ms"); // ThreadLocal 的情况 for (int i = 0; i < THREAD_COUNT; ++i) { futs[i] = exe.submit(new RndTask(1)); } totaltime = 0; for (int i = 0; i < THREAD_COUNT; ++i) { totaltime += futs[i].get(); } System.out.println("使用 ThreadLocal 包装 Random 实例:" + totaltime + "ms"); exe.shutdown(); } }
publicclassAtomicIntegerDemo{ static AtomicInteger i = new AtomicInteger();
publicstaticclassAddThreadimplementsRunnable{
@Override publicvoidrun(){ for (int k = 0; k < 10000; ++k) i.incrementAndGet(); } }
publicstaticvoidmain(String[] args)throws InterruptedException { Thread[] ts = new Thread[10]; for (int k = 0; k < 10; ++k) { ts[k] = new Thread(new AddThread()); } for (int k = 0; k < 10; ++k) ts[k].start(); for (int k = 0; k < 10; ++k) ts[k].join(); System.out.println(i); } }
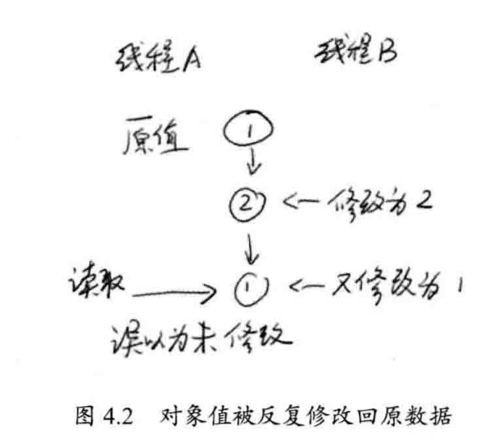
compareAndSwapInt 方法的内部,使用 CAS 原子指令,此外,『Unsafe』类还提供了一些方法:
1 2 3 4 5 6 7 8 9 10 11 12
// 获得给定对象偏移量上的 int 值 publicnativeintgetInt(Object o, long offset); // 设置给定对象偏移量上的 int 值 publicnativevoidputInt(Object, long offset, int x); // 获得字段在对象中的偏移量 publicnativelongobjectFieldOffset(Field f); // 设置给定对象的 int 值,使用 volatile 语义 publicnativevoidputIntVolatile(Object o, long offset, int x); // 获得给定对象的 int 值,使用 volatile 语义 publicnativeintgetIntVolatile(Object o, long offset); // 和 putIntVolatile 一样,但是要求被操作字段是 volatile 类型 publicnativevoidputOrderedInt(Object o, long offset, int x);
// 比较设置参数依次:期望 新值 期望时间戳 新时间戳 publicbooleancompareAndSet(V expectedReference, V newReference, int expectedStamp, int newStamp); // 获取当前对象引用 public V getReference(); // 获取当前时间戳 publicintgetStamp(); // 设置当前对象引用和时间戳 publicvoidset(V newReference, int newStamp);
它的本质是对 int[] 的封装,使用『Unsafe』类通过 CAS 的方式控制 int[] 在多线程下的安全性,其核心 Api 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
// 获得数组第i个下标元素 publicfinalintget(int i); // 获得数组长度 publicfinalintlength(); // 将数组第i个下标设置成newValue,并返回旧值 publicfinalintgetAndSet(int i, int newValue); // 进行CAS操作,如果第i个下标是expect,则设置成update,设置成功返回true publicfinalbooleancompareAndSet(int i, int expect, int update); // 将第i个下标的元素加1 publicfinalintgetAndIncrement(int i); // 将第i个下标的元素减1 publicfinalintgetAndDecrement(int i); // 将第i个下标的元素增加delta publicfinalintgetAndAdd(int i, int delta);
publicclassAtomicIntegerArrayDemo{ static AtomicIntegerArray arr = new AtomicIntegerArray(10);
publicstaticclassAddThreadimplementsRunnable{ @Override publicvoidrun(){ for (int k = 0; k < 10000; ++k) { arr.getAndIncrement(k % arr.length()); } } }
publicstaticvoidmain(String[] args)throws InterruptedException { Thread[] ts = new Thread[10]; for (int k = 0; k < 10; ++k) { ts[k] = new Thread(new AddThread()); } for (int k = 0; k < 10; ++k) { ts[k].start(); } for (int k = 0; k < 10; ++k) { ts[k].join(); } System.out.println(arr); }
『AtomicIntgerFieldUpdater』类可以在不改动原有代码基础上,让普通变量享受 CAS 带来的线程安全性,这个「Updater」有三种,分别是『AtomicIntegerFieldUpdater』、『AtomicLongFieldUpdater』、『AtomicReferenceFieldUpdater』它们可以对『int』、『long』以及普通对象进行 CAS 修改。
// 检查Updater是否工作正确 publicstatic AtomicInteger allScore = new AtomicInteger(0);
publicstaticvoidmain(String[] args)throws InterruptedException { final Candidate stu = new Candidate(); // 假设只有一个候选人 Thread[] t = new Thread[10000]; for (int i = 0; i < 10000; ++i) { t[i] = new Thread() { @Override publicvoidrun(){ if (Math.random() > 0.4) { scoreUpdater.incrementAndGet(stu); allScore.incrementAndGet(); } } }; t[i].start(); } for (int i = 0; i < 10000; ++i) t[i].join(); System.out.println("score=" + stu.score); System.out.println("allScore=" + allScore); } }
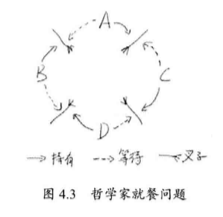
publicstaticvoidmain(String[] args)throws InterruptedException { DeadLock A = new DeadLock(fork1); DeadLock B = new DeadLock(fork2); A.start(); B.start(); Thread.sleep(1000); } }