1. 单例模式
不再赘述
2. 不变模式
重点在于给类加上「final」关键字,使其无法拥有子类。
1
2
3
4
5
6
7
8
9
10
|
java.lang.String
java.lang.Boolean
java.lang.Byte
java.lang.Character
java.lang.Double
java.lang.Float
java.lang.Integer
java.lang.Long
java.lang.Short
|
不变模式通过回避问题而不是解决问题的方式来处理多线程并发访问控制。
3. 生产者-消费者模式
- 生产者线程负责提交用户请求
- 消费者线程负责处理生产者提交的任务
- 生产者和消费者共享内存缓存区进行通信。
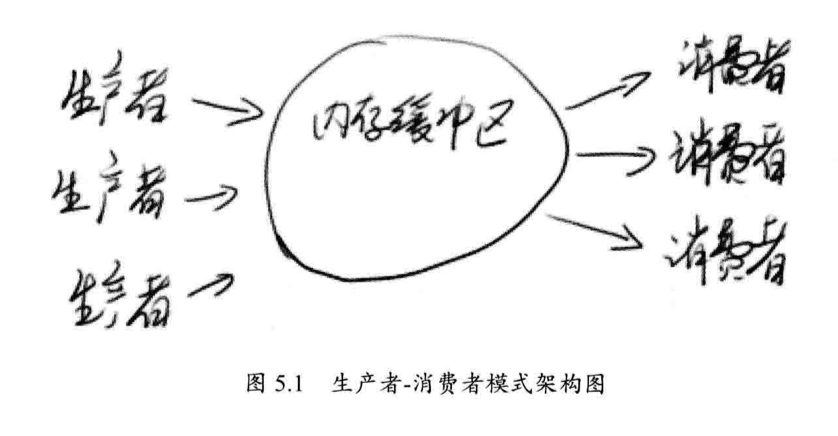
上图中,三个「生产者」将任务提交到「共享内存缓存区」,「消费者」不直接和生产者线程通信,而是在共享内存缓存区中获取任务,并进行处理。
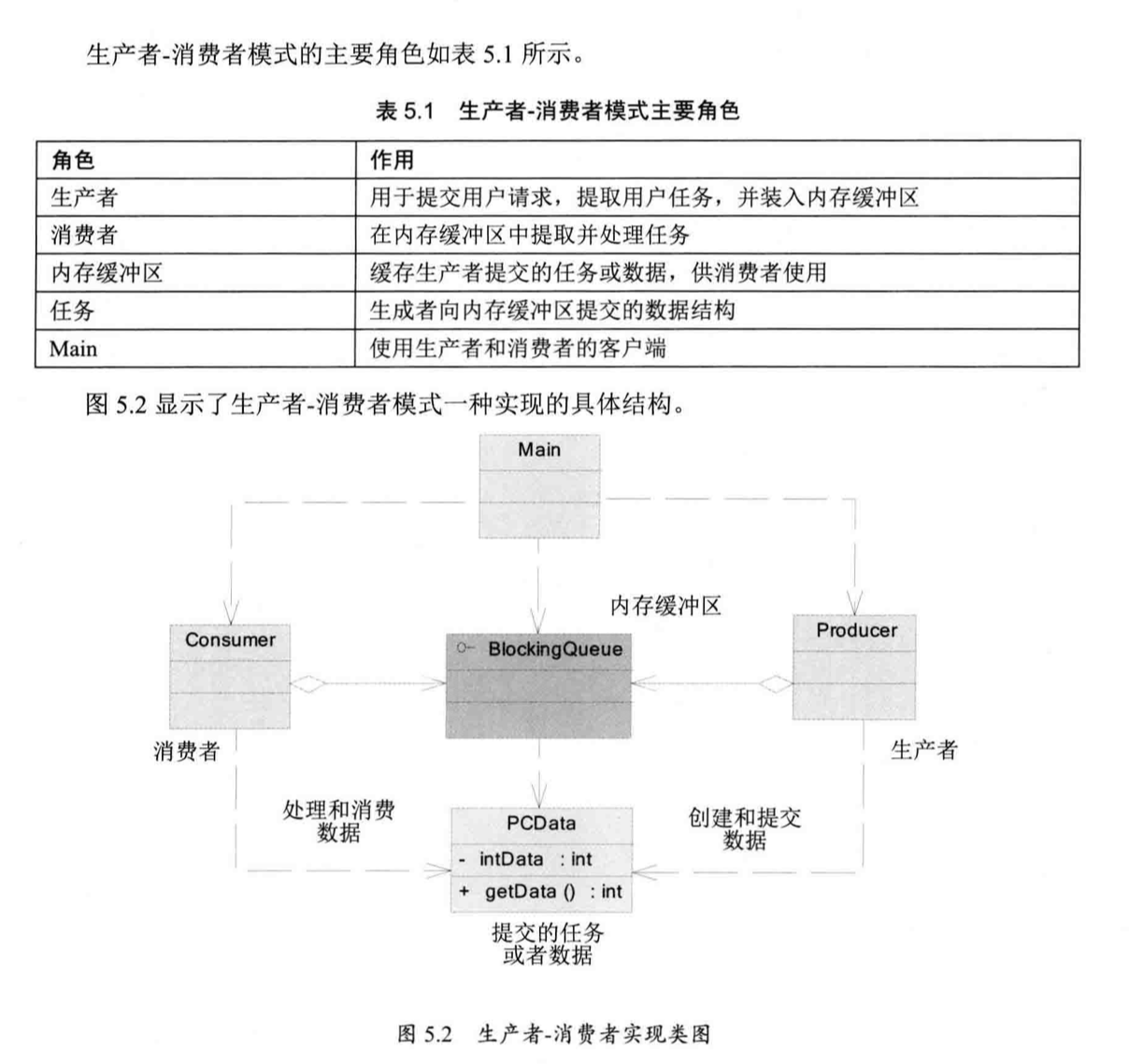
这里使用了『BlockingQueue』充当内存缓存区,维护任务和数据队列,『PCData』充当一个生产任务,「生产者」和「消费者」将引用同一个『BlockingQueue』实例。
生产者消费者模式对「生产者」和「消费者」线程进行了解耦,优化了系统整体结构,又由于缓存区的作用,允许「生产者」和「消费者」在执行上的性能差异,从一定程度上环节了性能瓶颈对系统性能的影响。
4. 无锁生产者-消费者模式
『BlockingQueue』是一个不错的选择,但是并不是一个高性能的实现,它完全使用锁和阻塞来实现线程间同步,高并发场合『ConcurrentLinkedQueue』是一个高性能队列,使用『BlockingQueue』仅仅是为了方便数据共享。
而『ConcurrentLinkedQueue』成功的秘诀在于大量使用了无锁的 CAS 操作,使用 CAS 来进行编程非常困难,目前有一个现成的 Disruptor 框架,它已经实现了这个功能。
4.1 无锁缓存框架:Disruptor
它使用环形队列实行一个数组,只需要一个当前位置的指针即可,这个指针用于出队和入队,由于环形队列,总大小需要预先指定,不能动态扩展,为了快速从一个序列 sequence 对应到数组的实际位置,需要数组大小是2的整数次方,这样通过 sequence & (queueSize - 1) 就能立即定位实际的元素位置 index ,这要比取模快得多。
queueSize 是2的整数次方,这样通过这行代码就能将 sequence 限定在 queueSize - 1 的范围内,不会有任何一位浪费。
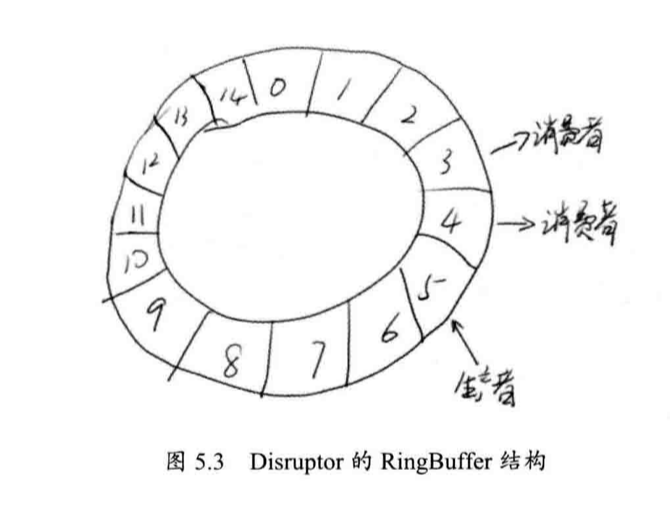
现在,「生产者」写入数据的时候使用 CAS 操作,「消费者」读取数据的时候,为了防止多个「消费者」同时处理一个数据,也使用 CAS 进行数据保护。
另外一个好处就是完全做到内存复用,不会有新的空间需要分配或者老的空间需要回收,大大减少系统分配空间以及回收空间的额外开销。
5. Future 模式
Future 模式是多线程中非常常见的设计模式,核心思想是异步调用。
我们对比一下传统的程序调用流程:
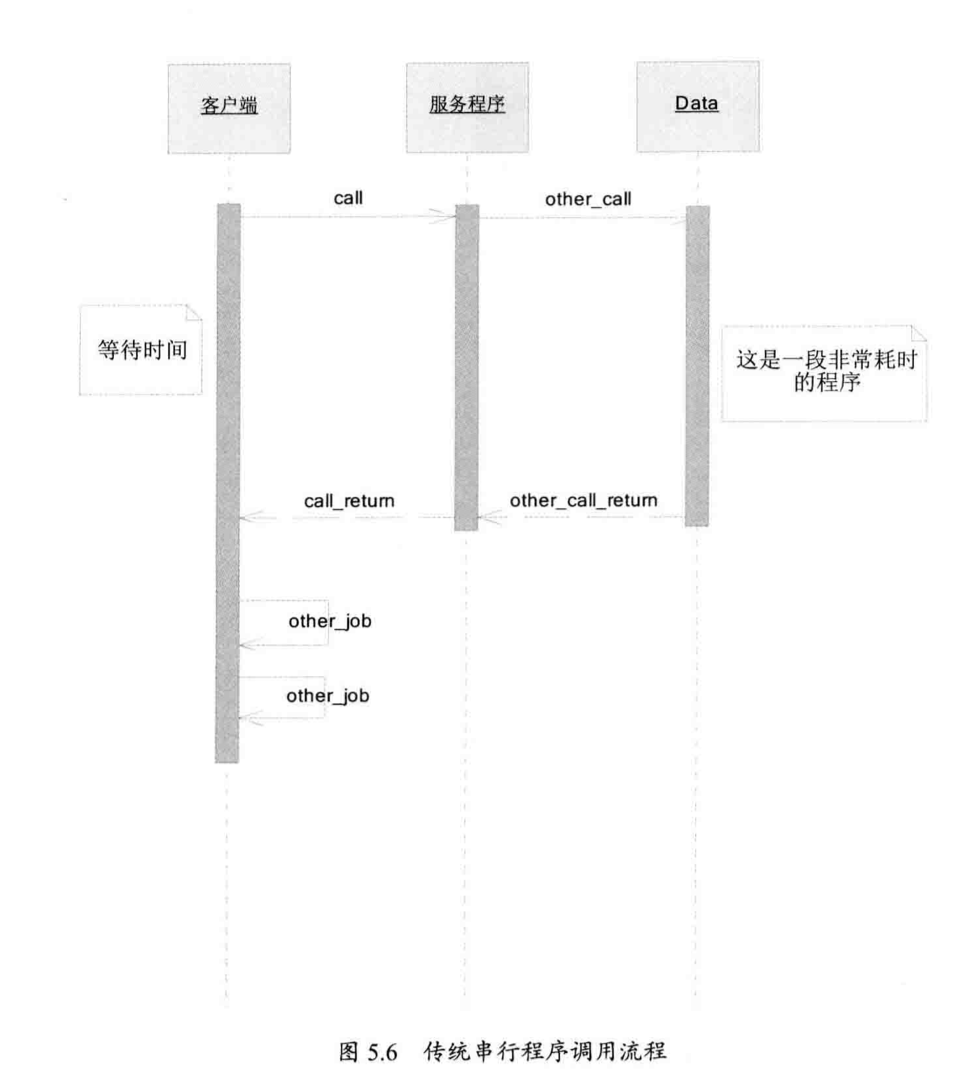
然后再看看广义 Future 模式的实现,虽然 call 本身的执行时间很长,但是服务程序不等数据处理完成便立即返回客户端一个伪造的数据。
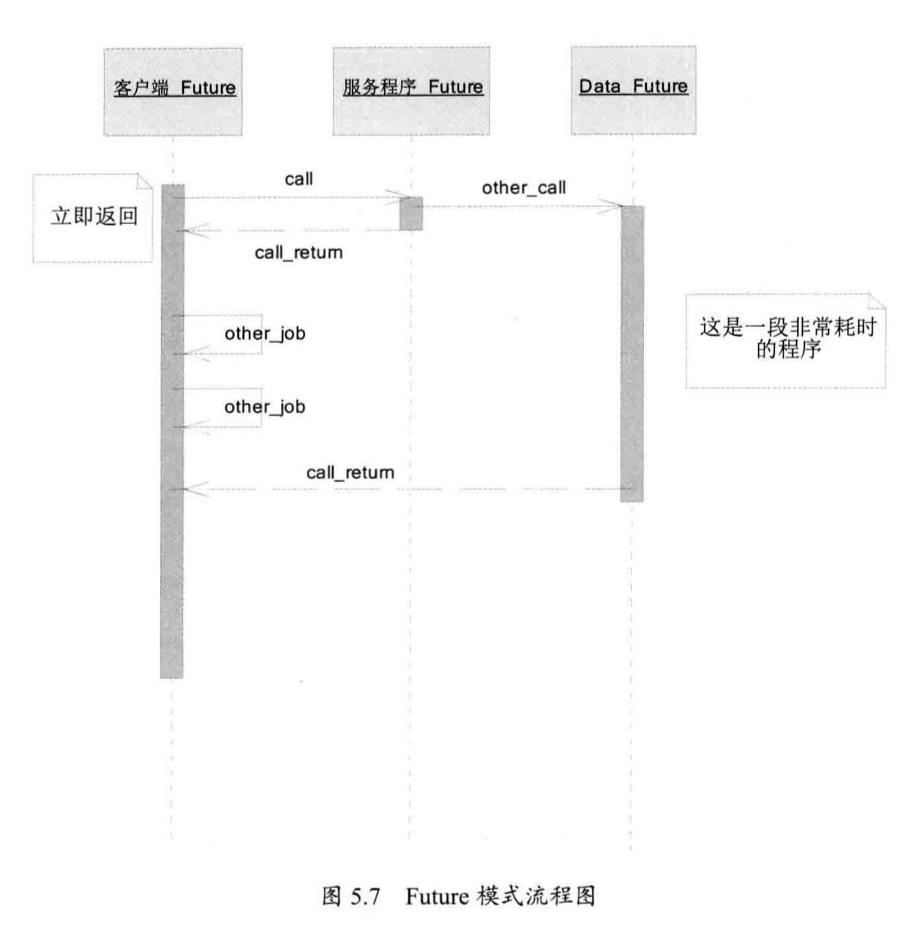
5.1 Future 模式的主要角色

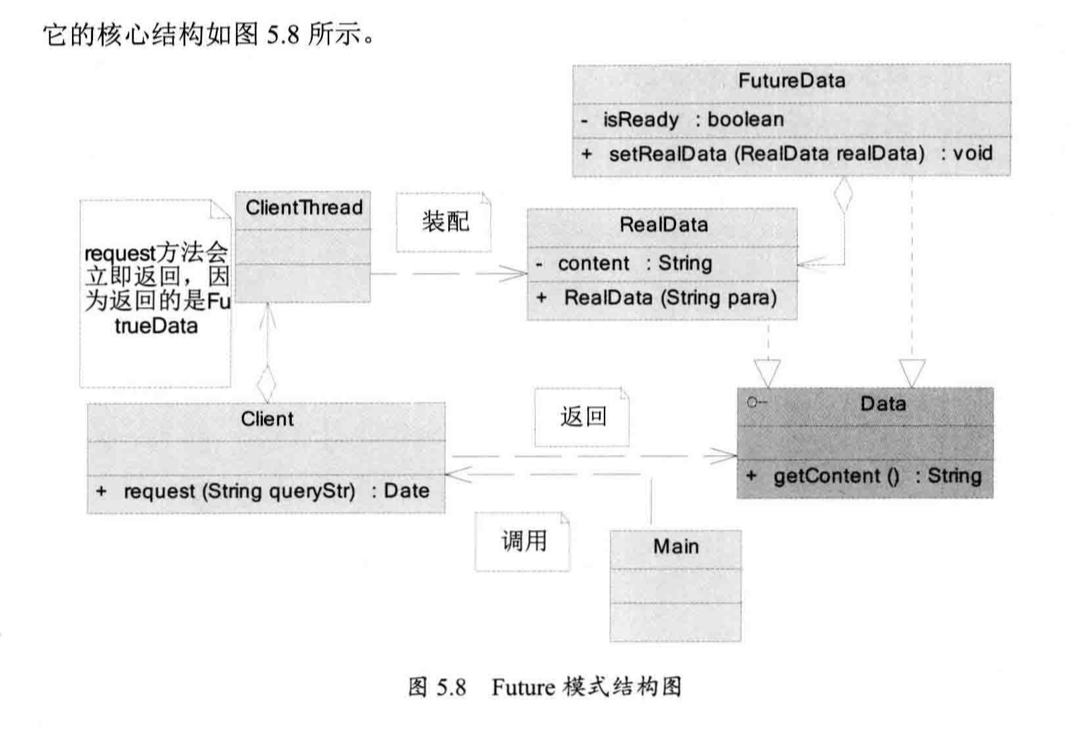
5.2 Future 模式简单实现
「RealData」是最终使用的数据模型,它的构造很慢,「FutureData」是 Future 模式的关键,它是真实数据的代理,封装了「RealData」的等待过程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public class FutureData implements Data {
protected RealData realdata = null;
protected boolean isReady = false;
public synchronized void setRealData(RealData realdata) {
if (isReady) {
return;
}
this.realdata = realdata;
ready = true;
notifyAll();
}
public synchronized String getResult(){
while (!isReady) {
try {
wait();
} catch (InterruptedException e) {}
}
return realdata.result;
}
}
|
5.3 JDK 中的 Future 模式
JDK 已经在内部准备好了一套完整的实现:
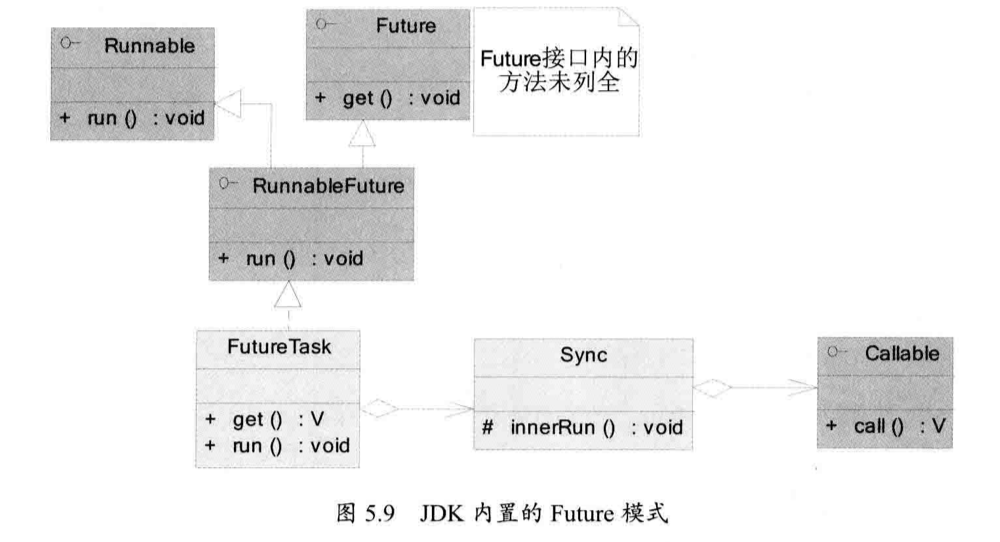
其中『Future』接口就类似于前文描述的订单或者说是契约。通过它,你可以得到真实的数据。『RunnableFuture』继承了『Future』和『Runnable』两个接口,其中 run 方法用于构造真实的数据。
它有一个具体的实现『FutureTask』类。『FutureTask』有一个内部类『Sync』,一些实质性的工作,会委托『Sync』类实现。而『Sync』类最终会调用『Callable』接口,完成实际数据的组装工作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| public class FutureMain {
static class RealData implements Callable<String> {
private String data;
public RealData(String data) {
this.data = data;
}
@Override
public String call() {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < 10; ++i) {
sb.append(data);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
}
}
return sb.toString();
}
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<String> future = new FutureTask<>(new RealData("a"));
ExecutorService executor = Executors.newFixedThreadPool(1);
executor.submit(future);
System.out.println("请求完毕");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
}
System.out.println("数据:" + future.get());
}
}
|
6. 并行流水线
假设我们现在要计算 $(B+C)*B/2$ ,但是因为 $B+C$ 没有完成,数据之间存在依赖性,无法进行并行化,此时,我们可以参考「流水线思想」。
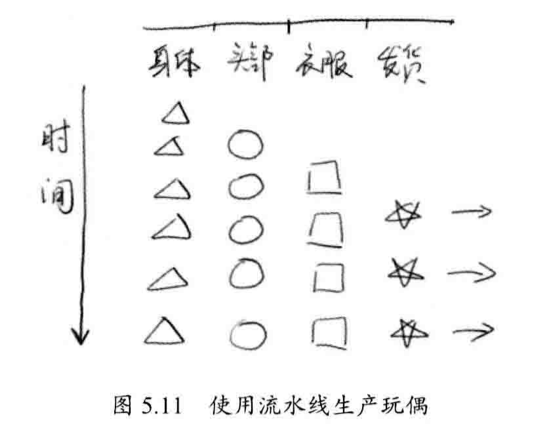
即使上面的式子我们无法并行,但是如果有一大堆的 B 和 C ,我们可以使用流水线,将该计算流程分为三步:
- A = B + C
- D = A X B
- D = D / 2
上述三步可以使用三个线程单独计算。
7. 并行搜索
搜索是一个软件并不可少的功能,对于有序的数据,通常采用二分搜索,对于无序数据,只能挨个查找。
一种简单的策略,是将数据分割,如果使用两个线程并行,则分成两个数组,每个数组独立搜索。
8. 并行排序
这里有几种相对简单,但也足以让人脑洞大开的排序算法。
8.1 奇偶交换排序
对于一般的冒泡,我们使用下面的代码:
1
2
3
4
5
6
7
8
9
10
11
| public static void bubbleSort(int[] arr) {
for (int i = arr.length - 1; i > 0; --i) {
for (int j = 0; j < i; ++j) {
if (arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
|
流程如下:

问题在于,这样排序很难并行化,因此可以进行分离,对于奇交换而言,总是比较奇搜索以及其相邻的后续元素;而偶交换总是比较偶索引和其相邻的后续元素,如下所示:

8.2 改进插入排序:希尔排序
插入排序的思想是:一个数组分成两个部分,一部分是排序的,一部分是未排序的,把未排序的内容插入排序的部分,实现排序的效果。
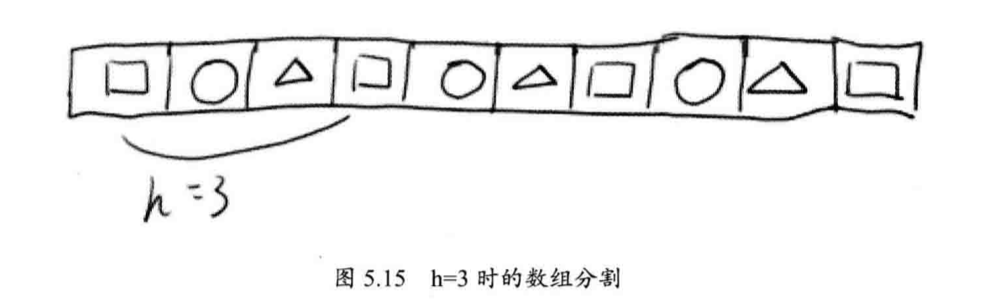
简单插入很难实现并行化,因此,我们对其扩展,就是希尔排序,对整个数组间隔 h 分割为多个子数组,数组互相插在一起,每次对一个子数组排序;每一组排序完成,递减 h 的值,进行下一轮排序,直到 h 为1。
9. 矩阵乘法
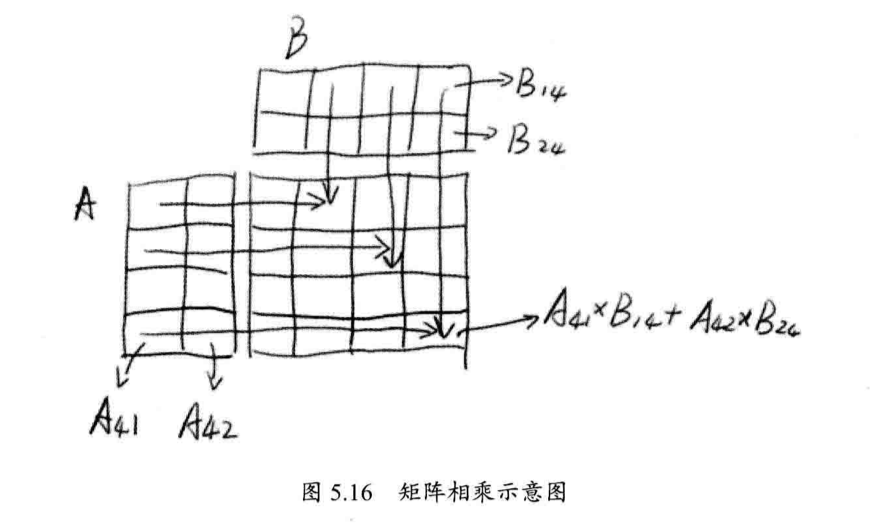
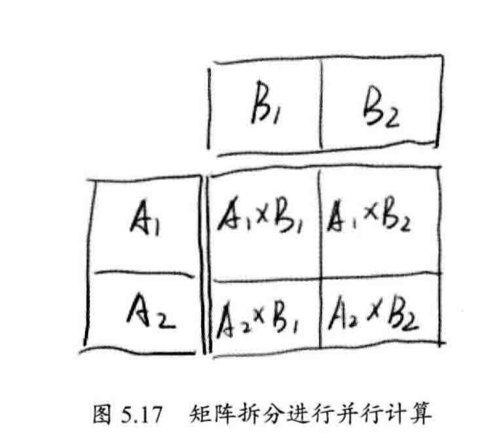
这个很好理解,分割矩阵即可。
10. NIO
NIO 是 New IO 的简称,涉及通道和缓存区。
10.1 基于 Socket 的服务端多线程模式
服务端多线程处理的结构如下:
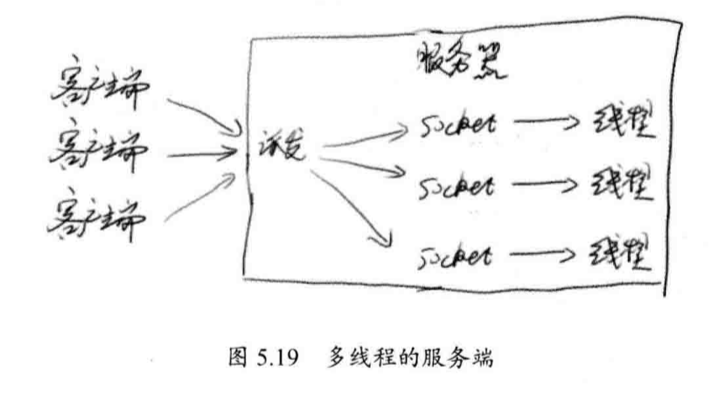
服务器为每一个客户端连接启动一个线程,为了接受客户端连接,服务器还需要一个派发线程。
结果自然是慢吞吞的,因为服务器先读入客户端的输入,而客户端缓慢的处理速度,使得服务端花费不少时间用于等待。
下面看看服务端 Demo 吧:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| public class SocketDemo {
private static ExecutorService tp = Executors.newCachedThreadPool();
static class HandleMsg implements Runnable {
Socket clientSocket;
public HandleMsg(Socket clientSocket) {
this.clientSocket = clientSocket;
}
public void run() {
BufferedReader is = null;
PrintWriter os = null;
try {
is = new BufferedReader(new InputStreamReader(clientSocket.getInputStream()));
os = new PrintWriter(clientSocket.getOutputStream(), true);
String inputLine = null;
long b = System.currentTimeMillis();
while ((inputLine = is.readLine()) != null) {
System.out.println(inputLine);
os.println(inputLine);
}
long e = System.currentTimeMillis();
System.out.println("spend" + (e - b) + "ms");
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (is != null) is.close();
if (os != null) os.close();
clientSocket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) {
ServerSocket echoServer = null;
Socket clientSocket = null;
try {
echoServer = new ServerSocket(8000);
} catch (IOException e) {
System.out.println(e);
}
while (true) {
try {
clientSocket = echoServer.accept();
System.out.println(clientSocket.getRemoteSocketAddress() + " connect!");
tp.execute(new HandleMsg(clientSocket));
} catch (IOException e) {
System.out.println(e);
}
}
}
}
|
然后是客户端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| public class SocketClientDemo {
public static void main(String[] args) throws IOException {
Socket client = null;
PrintWriter writer = null;
BufferedReader reader = null;
try {
client = new Socket();
client.connect(new InetSocketAddress("localhost", 8000));
writer = new PrintWriter(client.getOutputStream(), true);
writer.println("hello");
writer.flush();
reader = new BufferedReader(new InputStreamReader(client.getInputStream()));
System.out.println("from server: " + reader.readLine());
} catch (IOException e) {
e.printStackTrace();
} finally {
if (writer != null) writer.close();
if (reader != null) reader.close();
if (client != null) client.close();
}
}
}
|
它的致命弱点就是客户端输入缓慢,服务端一直等待,主要时间都花费在等待上。
10.2 使用 NIO 进行网络编程
通道,类似于流,一个「Channel」可以和文件或者网络「Socket」对应,和它一起使用的另外一个组件是「Buffer」,可以理解成一个内存区域或者 byte 数组,数据包装成「Buffer」的形式才能和「Channel」进行交互。
另外一个和「Channel」相关的是「Selector」,在「Channel」众多实现中,有一个是「SelectableChannel」,表示可被选择的通道,任何一个「SelectableChannel」可以被注册到一个「Selector」中,这样一个「Channel」就能被「Selector」所管理,而一个「Selector」可以管理多个「SelectableChannel」,当「SelectableChannel」数据准备好了,「Selector」就会接到通知,得到已经准备好的数据。
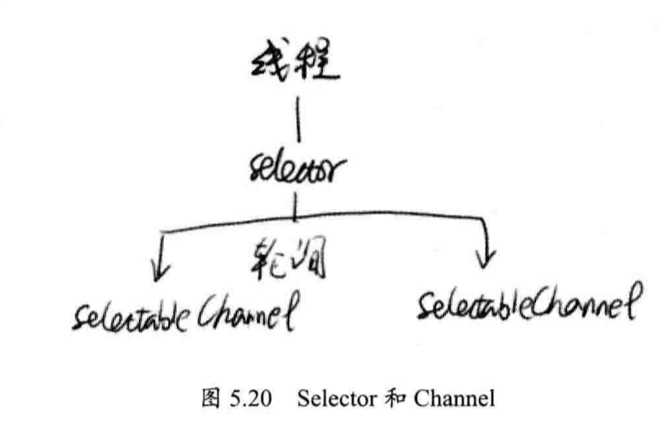
当与客户端连接的数据没有准备好时,「Selector」处于等待状态,一旦任何一个「Channel」准备好了数据,「Selector」就能立即得到通知,获取数据并处理。
11. AIO
这是异步 IO 的缩写,即 Asynchronized 。对于 AIO 而言,它不是在 IO 准备好时通知线程,而是 IO 操作完成以后,再通知线程,因为它完全不会阻塞。
使用特殊的『AsynchronousServerSocketChannel』实现。