Java 8与并发
1. Java 8的函数式编程
JS 既不是严格意义上的函数式编程,也不是严格意义上的面向对象,如果我们愿意,它可以被作为面向对象,也可以被作为函数式语言,这样的语言就是多范式语言。
1.1 函数作为一等公民
看一段 JS 代码:
1 | $("button").click(function() { |
这段代码里,我们使用了 each() 这个函数,把一个函数作为一个函数的参数,是函数式编程的特性之一。
再一个例子:
1 | function f1() { |
这段代码里,它返回了函数 f2 ,在之后的使用中,我们发现这个「result」就是一个函数,函数可以作为另外一个函数的返回值,也是函数式编程的重要特点。
1.2 无副作用
所谓「副作用」是指在函数的调用过程中,除了给出了返回值外,还修改了函数外部的状态。
函数的副作用应该被尽可能去除,但是完全无副作用是做不到的,但是与面向对象相比,函数调用的副作用,在函数式编程中,应该被有效限制。
显式函数指函数与外界交换数据的唯一渠道就是参数与返回值。
显式函数不会去读取或者修改函数的外部状态。
隐式函数除了参数和返回值,还会读取外部信息,或者修改外部信息。
1.3 申明的 Declarative
相比命令式 Imperative 而言,命令式喜欢大量使用可变对象和指令,而现在,我们不再需要明确的指令操作,我们要做的,仅仅是提出要求,申明我们的用意即可。
对比一个例子。下面是传统的命令式语句:
1 | public static void imperative() { |
与之对应的,我们的申明式的语句:
1 | public static void declarative() { |
我们的循环体不见了!而 println 中没有任何参数,我们仅仅说明我们的用意,这些循环以及判断被简单封装到我们的程序库中。
1.4 不变的对象
在函数式编程中,几乎所有传递的对象都不会被轻易修改。
1 | static int[] arr = {1, 3, 4, 5, 6, 9, 8, 7, 4 ,2}; |
这段代码在将「arr」每一个值加一并打印以后,我们查看原本的数组,发现数组并没有变化,在函数式编程中,这种状态是一种常态,几乎所有对象都拒绝被修改,这非常类似不变模式。
1.5 易于并行
由于对象都是不变状态,因此更容易进行并行,而不用考虑安全问题。这也得益于不变模式。
1.6 更少的代码
通常,函数式编程更加简明扼要,引入函数式以后,我们可以使用更少的代码来完成 Java 的开发。
下面的代码判断数组中每一个成员是奇数或者偶数,并将奇数加一:
1 | static int[] arr = {1, 3, 4, 5, 6, 9, 8, 7, 4 ,2}; |
使用函数式方式:
1 | Arrays.stream(arr).map(x -> (x % 2 == 0 ? x : x + 1)).forEach(System.out::println); |
2. 函数式编程基础
2.1 FunctionalInterface 注释
Java 8提出了函数式接口的概念,所谓函数式接口,就是只定义一个单一抽象方法的接口:
1 |
|
它表明这个接口是函数式接口,而这个注释实际上是可有可无的,因为编辑器会给满足条件的接口加上这个注释。
值得注意的是函数式接口只能有一个抽象方法,而不是只能有一个方法。这分两点说明:
- 在 Java 8中,接口运行存在实例方法。
- 其次任何被『java.lang.Object』实现的方法,都不能视为抽象方法。
下面的『NonFunc』接口不是函数式接口,因为 equals() 方法『java.lang.Object』中已经实现了:
1 | interface NonFunc { |
同理,下面实现的『IntHandler』接口符合函数式接口的要求,虽然看起来不像:
1 |
|
函数式接口的实例可以由方法引用或者 lambda 表达式来构造。
2.2 接口默认方法
在 Java 8之前的版本中,接口只能包含抽象方法,但在 Java 8之后,接口也可以包含若干实例方法,一个对象实例,将拥有来自多个不同接口的实例方法。
比如,对于接口『IHourse』,实现如下:
1 | public interface IHourse { |
在 Java 8中,可以使用「default」关键字,可以在接口内定义实例方法。这个方法并非抽象方法,而是拥有特定逻辑的具体实例方法。所有动物都能自由呼吸,所以,这里可以再定义一个『IAnimal』接口,它也包含一个默认的方法 breath() :
1 | public interface IAnimal { |
骡是马和驴的杂交物种,因此『Mule』可以实现为『IHorse』,同时它也是动物:
1 | public class Mule implements IHorse, IAnimal { |
上面代码中『Mule』同时拥有来自不同接口的实现方法,这在 Java 8之前是不能办到的,从某种程度上说,这种模式弥补了 Java 单一继承的一些不便,但同时它将面临和多继承相同的问题,如果『IDonkey』也存在一个默认的 run() 方法,那么同时实现它们的『Mule』,就会不知所措:
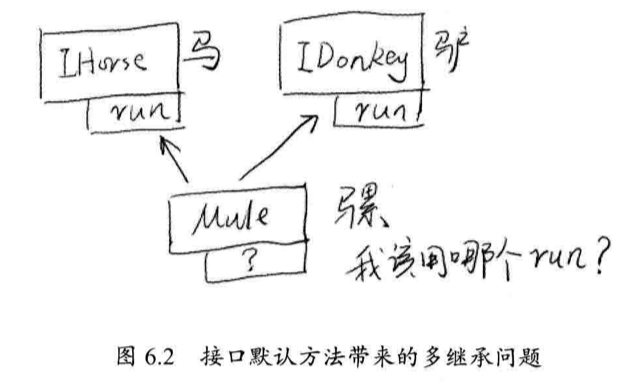
现在实现一个『IDonkey』的实现:
1 | public interface IDonkey { |
我们修改『Mule』的实现,注意它同时实现了『IHorse』和『IDonkey』:
1 | public class Mule implements IHorse, IDonkey, IAnimal { |
此时,因为两个接口『IHorse』和『IDonkey』都有方法 run() 因此编译器将报错。
因此,我们不得不重新实现以下 run() 方法,让编译器可以进行方法绑定:
1 | public class Mule implements IHorse, IDonkey, IAnimal { |
接口默认实现对于整个函数式编程的流式表达非常重要,比如我们熟悉的『java.util.Comparator』接口,它在 Jdk1.2 时被引入,用于在排序时给出两个对象实例的具体比较逻辑,在 Java 8中,『Comparator』接口新增了若干默认方法,用于多个比较器的整合,其中一个常用的默认方法如下:
1 | default Comparator<T> thenComparing(Comparator<? super T> other) { |
有了这个默认方法,在进行排序的时候,我们可以非常方便地进行元素的多条件排序,比如如下代码构造一个比较器,它先按照字符串长度排序,继而按照大小写不敏感的字母顺序排序:
1 | Comparator<String> cmp = Comparator.comparingInt(String::length).thenComparing(String.CASE_INSENSITIVE_ORDER); |
2.3 lambda 表达式
lambda 表达式即匿名表达式,它是一段没有函数名的函数体,下面在 forEach() 中,传入一个 lambda 表达式,它完成了对元素的标准输出操作,可以看出这段表达式并不像函数一样有名字,非常类似匿名内部类。
1 | List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6); |
和匿名对象一样,lambda 表达式也可以访问外部的局部变量,如下所示:
1 | final int num = 2; |
但是有一个限制,访问的外部变量需要是「final」的,但是如果我们将上面的关键字「final」去掉,编译还是可以通过,这是因为 lambda 表达式将使用的变量认为是「final」的,如果这样写,就不行了:
1 | int num = 2; |
上述代码将会因为 num++ 而报错。
2.4 方法引用
方法引用是 Java 8提出的用来简化 lambda 表达式的一种手段,方法引用再 Java 8中使用非常灵活,可以分为以下几种:
- 静态方法引用:
ClassName::methodName - 实例上的实例方法引用:
instanceReference::methodName - 超类上的实例方法引用:
super::methodName - 类型上的实例方法引用:
ClassName::methodName - 构造方法引用:
Class::new - 数组构造方法引用:
TypeName[]::new
首先,方法引用使用 :: 定义,前半部分是类名或者实例名,后半部分是方法名,如果是构造函数则使用 new 表示。
1 | public class InstanceMethodRef { |
这里调用每一个『User』对象实例的 getName() 方法,并将这些『User』的「name」作为一个新的流。
有时候编辑器也会困扰,在同时拥有实例方法和静态方法的时候:
1 | public class BadMethodRef { |
代码会有编辑器警告,这是因为在『Double』中有两个
toString(),存在歧义。
方法引用也可以直接使用构造函数比如已经存在一个模型类『User』:
1 | class User { |
那么可以这么使用:
1 | // 函数式接口 |
以后我们使用 uf.create() 的方式来创建『User』了。
3. 一步步走入函数式编程
流对象,类似集合或者数组,它赋予我们遍历处理流内元素的功能。
早期我们这样写遍历代码:
1 | static int[] arr = {1, 3, 4, 5, 6, 7, 8, 9, 10}; |
Jdk 5引入了 for-each 循环,现在 Jdk 8引入了「流」:
1 | public static void main(String[] args) { |
函数 forEach 将循环过程包装,挨个送入『IntConsumer』,除了『IntStream』,还有『DoubleStream』、『LongStream』和普通对象流 Stream ,而这些不同的流就决定了不同的「Consumer」,任性的程序员说:既然 forEach 的参数可以从上下文得到,我们就不写「Consumer」了。
1 | public static void main(String[] args) { |
但是,既然是『IntConsumer』接口,参数自然是『int』啊,代码进一步缩减:
1 | public static void main(String[] args) { |
但是为了一句执行多个花括号也没必要呀:
1 | public static void main(String[] args) { |
编译发现,内部实现了一个私有的静态方法,等同于实现一个匿名类。
我们知道 Java 8支持方法引用:
1 | public static void main(String[] args) { |
我们连参数申明和传递都省略了…你已经是一个成熟的编译器了,该学会自己写代码了。
lambda 表达式还可以使用更流畅的流式 API 对各种组件进行更自由的搭配。下面的例子,一次输出标准错误,一次输出标准输出:
1 | public static void main(String[] args) { |
其中 andThen 方法会一个一个『Consumer』进行执行,从而实现多个处理器的整合,这是一个惯用套路。
4. 并行流与并行排序
4.1 并行流过滤数据
1 | // 非常普通的判断素数,可以用快速线性筛 |
我们用 lambda 表达式来写:
1 | IntStream.range(1, 1000000).filter(PrimeUtil::isPrime).count(); |
上面是串行计算,我们用并行来做:
1 | IntStream.range(1, 1000000).parallel().filter(PrimeUtil::isPrime).count(); |
个人认为 stream 相关的函数也可以认为是 lambda 表达式,因为 stream 内部就是用了 lambda 表达式实现的。
4.2 从集合得到并行流
下面这段代码试图统计集合中所有学生的平均分:
1 | List<Student> ss = new ArrayList<Student>(); |
我们希望使用并行处理:
1 | double ave = ss.parallelStream().mapToInt(s -> s.score).average().getAsDouble(); |
将原来的代码改造成并行化是非常方便的。
4.3 并行排序
我们熟悉的排序有 Arrays.sort() 排序,这是串行的,我们还有 Arrays.parallelSort() 来进行并行排序。
1 | int[] arr = new int[10000000]; |
除了并行排序,还有一些 API 可以作用于数组中数据的赋值,比如:
1 | public static void setAll(int[] array, IntUnaryOperator generator); |
这是一个函数式味道很浓的接口,第二个参数是一个函数式接口,如果我们希望给数组的每一个元素附上一个随机数,那么可以这么做:
1 | Random r = new Random(); |
5. 增强的 Future:CompletableFuture
『CompletableFuture』是 Java 8的一个超大型工具类,一方面是它实现了『Future』接口,另外它实现了『CompletionStage』接口。这个接口有约40种方法!它是为了流式调用准备的,通过这个接口,我们可以在一个执行结果上进行多次流式调用。
1 | stage.thenApply(x -> square(x)).thenAccept(x -> System.out.print(x)).thenRun(() - > System.out.println()); |
这一连串将挨个执行。
5.1 完了通知我
『CompletableFuture』和『Future』一样,可以作为函数调用的契约,如果我们向它请求一个数据,如果没有准备好,那么线程会等待,不同的是,我们可以手动设置『CompletableFuture』的完成状态。
1 | public class AskThread implements Runnable { |
这个『AskThread』线程的作用是计算『CompletableFuture』表示的数字的平方。
5.2 执行异步请求
通过『CompletableFuture』提供的进一步封装,我们可以实现「Future」那样的异步调用:
1 | public class CompletableFutureAsyDemo { |
这里的 supplyAsync 会立即返回,它返回的『CompletableFuture』实例就是本次调用的契约,在将来的任何场合,用于获取最终的结果,若直接试图 get 那么线程将等待。
与之相对的,还有一个 runAsync 方法,这个方法没有返回值,仅仅简单执行一个异步动作。
但是这些都需要指定一个『Executor』参数,如果不指定,就是在默认的公共的『ForkJoinPool.common』线程池中执行。
JDK1.8 中,新增了
ForkJoinPool.commonPool()方法,它获取一个公共的『ForkJoin』线程池,但是都是「Daemon」的线程。
5.3 流式调用
我们看看前面说的『CompletionStage』的约40个接口是如何使用的:
1 | CompletableFuture<Void> fu = CompletableFuture |
为什么我们总要执行
get()方法,因为异步调用的缘故,不等cal执行完,这个方法在「Daemon」线程中执行,就直接退出了。
5.4 CompletableFuture 中的异常处理
『CompletableFuture』提供一个异常处理的方法 exceptionally() ,看一下 demo :
1 | public static Integer calcExcption(Integer para) { |
5.5 组合多个 CompletableFuture
我们可以将多个『CompletableFuture』组合起来,一个方法是使用 thenCompose 方法,签名如下:
1 | public <U> CompletableFuture<U> thenCompose( |
一个『CompletableFuture』 完成后,会通过「Function」传递给下一个『CompletionStage』处理。
1 | CompletableFuture<Void> fuEx = CompletableFuture |
另外一个组合方式是使用 thenCombine() 方法:
1 | public <U,V> CompletableFuture<V> thenCombine( |
首先完成当前『CompletableFuture』和「other」的执行,接着,将两者的执行结果传递给『BitFunction』,并返回代表『BitFunction』实例的『CompletableFuture』对象:
1 | CompletableFuture<Integer> intFuture = CompletableFuture.supplyAsync(() -> calcExcption(50)); |
6. 读写锁改进:StampedLock
『StampedLock』是 Java 8新的锁机制,简单理解,它是读写锁的一个改进,它提供一个乐观的读策略,类似无锁,使得乐观锁完全不会阻塞写进程。
读写锁分离读和写,但是读和写之间还是有冲突。
6.1 StampedLock 使用例子
下面是一个小例子:
1 | public class StampedLockDemo { |
涨知识了,CAS 可不仅仅是
for(;;)这么简单。
6.2 StampedLock 的小陷阱
『StampedLock』内部使用 CAS 操作来循环反复尝试,在挂起线程的时候使用了 Unsafe.park() 这个方法挂起线程,中断就直接返回,不会抛出异常。这就导致了『StampedLock』没有处理中断的逻辑,会疯狂占用 CPU 。
6.3 StampedLock 实现思想
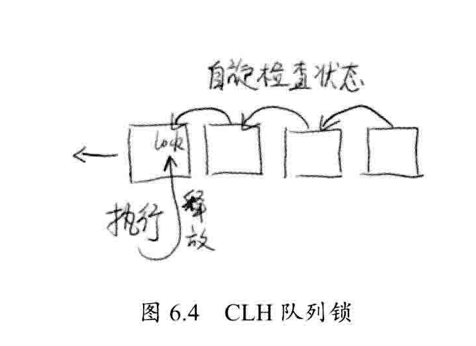
基于 CLH 锁,是一种自旋锁,它保证没有饥饿发生,保证 FIFO ,思想:维护一个等待线程队列,所有申请锁,但没有成功的线程都记录在这个队列中。每一个节点就是一个线程,保存一个标记位,用于判断当前线程是否已经释放锁。
当一个线程试图获得锁,取得当前等待队列的尾部节点作为其前序节点时,使用类似如下代码判断前序节点是否已经释放锁:
1 | while (pred.locked) {} |
- 只要前序节点没有释放,则当前节点不能执行,会自旋等待。
- 反之,前序释放,当前节点可以继续执行。
- 释放锁,也遵循这个逻辑,线程会叫标记设置为「false」,后续等待的线程就能继续执行了。
7. 原子类的增强
无锁的原子类操作使用系统的 CAS 指令,有着远超锁的性能,在 Java 8中引入了『LongAdder』类,这个类在『java.util.concurrent.atomic』包下,它也使用 CAS 指令。
7.1 更快的原子类:LongAdder
我们知道『AtomicInteger』是在一个死循环里面不断尝试修改,在大量修改失败后,这些原子操作的性能也是存疑的,一个基本思路是热点分离,将竞争的数据进行分解,虽然在 CAS 中没有锁,但是减小锁粒度这种分离热点的思想仍然可用。
我们可以仿造『ConcurrentHashMap』,将热点数据分离,我们在『AtomicInteger』内部核心数据「value」分离成一个数组,每个线程访问的时候,通过哈希映射其中一个数字进行计数,而最终的计数结果,则为这个数组的求和累加:
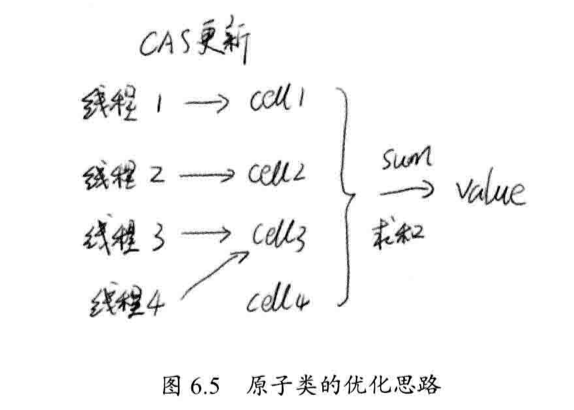
其中,热点数据「value」被分离成多个单元「cell」,每个「cell」单独维护内部的值,当前对象的实际值由所有的「cell」累计合成,这样,热点就进行了有效的分离,提高了并行度。
在实际操作中,『LongAdder』不会一开始就动用数组来进行处理,将所有数据标记在一个「base」数组里,大家修改都没有冲突也就没有必要扩展「cell」数组,但是一旦「base」有冲突,就初始化「cell」数组,如果「cell」上还有冲突,创建新的「cell」。
『LongAdder』的另外一个优化就是避免了伪共享,它的实现不是「padding」,而是一个新的注释 @sun.misc.Contended 。
class {int x ,int y}「x」和「y」被放在同一个高速缓存区,如果一个线程修改「x」;那么另外一个线程修改「y」,必须等待「x」修改完成后才能实施。
7.2 LongAdder 的功能增强版:LongAccumulator
它们有公共父类『Striped64』,因此内部优化是一样,都将一个『long』型整数进行分割,它是『LongAdder』的功能扩展,它不是一次执行一次加法,而是实现任意函数操作。
它的初始化:
1 | public LongAccumulator(LongBinaryOperator accumulatorFunction, long identity); |
第一个参数是需要执行的二元函数,第二个参数是初始值。
下面是 demo ,它通过多线程访问多个整数,返回最大的那个数:
1 | public class LongAccumulatorDemo { |