网站架构演进过程
中间件系统也是在大型网站的架构变化中出现并发展的。
访问量大的网站不一定是大型网站,大型网站应该有大量的数据,或者说是海量的数据,访问量和数据量缺一不可。
1.1 数据库与应用分离
我们关注的重点是随着数据量、访问量,网站也将因此产生结构上的变化,而不关注具体的业务功能点。
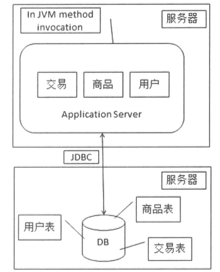
随着数据访问量不断增大,服务器的负载持续升高,此时我们可以通过将数据库和应用从一台机器分到两台机器上来进行优化,即数据库与应用分离。
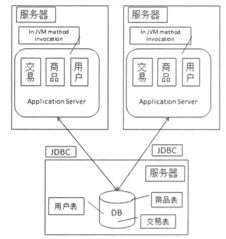
1.2 走向集群
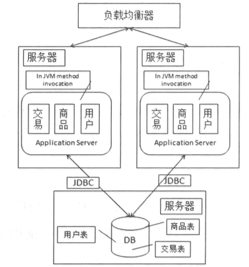
在增加一台服务器以后,可以通过 DNS 解决,也可以通过在服务器集群前增加负载均衡设备来解决。同时我们还需要处理 Session 问题。
这是加入负载均衡器以后的样子:
1.2.1 Session Sticky
对于 Session 问题,我们有多种解决方式。Web 服务器有多台以后,如果保证同一个会话的请求都在同一个 Web 服务器上处理,那么对于这个会话而言,它还是单机。
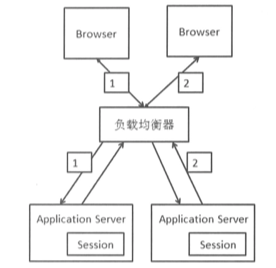
我们只需要在「负载均衡器」上动手脚,就可以办到。但是有许多问题:
- 如果一台 Web 服务器宕机,那么这台机器上的数据就会丢失;
- 会话标识是应用层的信息,「负载均衡器」要将「一个会话」的请求都保存在一个 Web 服务器上,就需要进行应用层的解析,这个开销比第4层的交换要大;
- 负载均衡器变为一个有状态的节点,要将会话保存到具体的 Web 服务器的映射,和无状态的节点相比,消耗内存更大,容灾更麻烦。
1.2.2 Session Replication
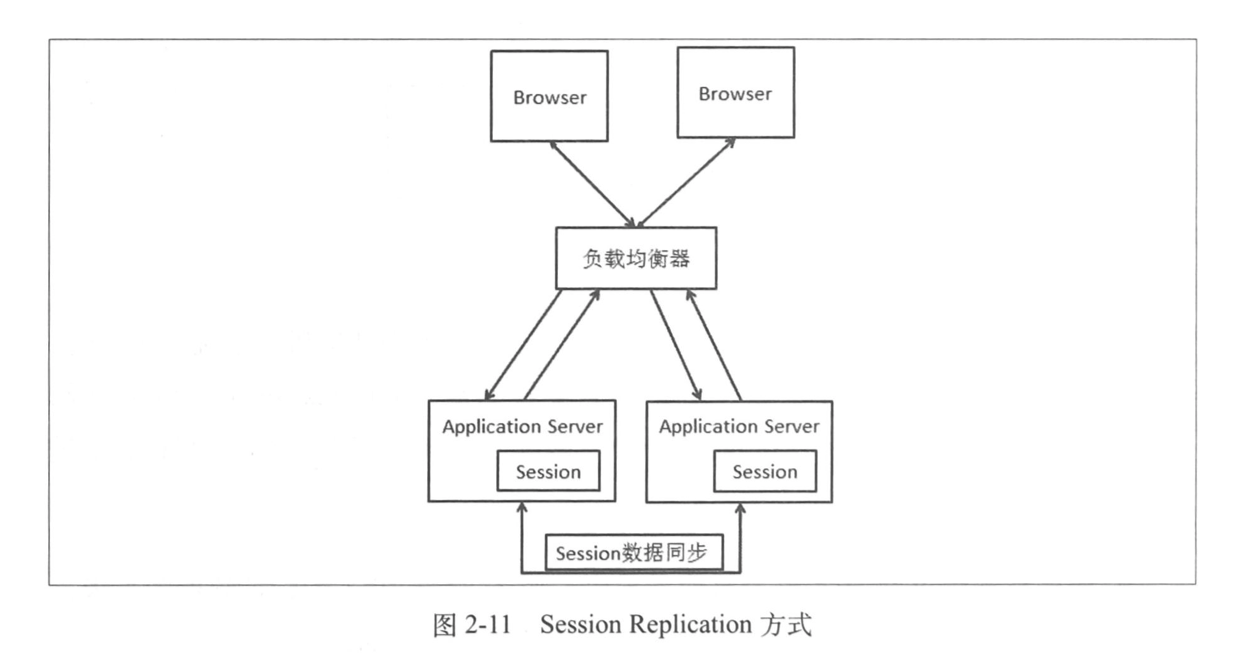
现在,不再要求负载均衡器来保证同一个会话的多次请求必须到同一个 Web 服务器上,而我们的 Web 服务器之间增加了会话的同步,通过同步就保证了不同 Web 服务器之间的 Session 数据一致。它的问题:
- 同步 Session 数据造成了网络带宽的开销,只要 Session 数据有变化,就需要将数据同步到所有的机器上,机器数越多,同步带来的网络带宽开销就越大;
- 每台 Web 服务器都要保存所有的 Session 数据,如果整个集群的 Session 数据很多的话,每台机器用于保存 Session 数据的内容占用会很严重。
如果只有几台机器,这个方案是可行的。
1.2.3 Session 数据集中存储

我们把 Session 数据集中存储起来,然后不同 Web 服务器从同样的地方来获取 Session ,会话请求经过负载均衡器后,不会固定在同样的 Web 服务器上,且 Web 服务器上不再需要 Session 数据复制了,它的问题:
- 读写 Session 引入了网络操作,这相对于本机的数据读取来说,问题在于存在时延和不稳定性,不过通信都发生在内网中,问题不是很大;
- 如果集中存储 Session 的机器或者集群出现问题,会影响我们的应用。
1.2.4 Cookie Based

所谓「Cookie Based」对于同一个会话的不同请求也是不限制具体处理机器的,它通过 Cookie 来传递 Session 数据。它的问题:
- Cookie 是有长度限制的,这也限制了 Session 数据的长度;
- 安全性,Session 数据本来是服务端的,这个方案可以对 Session 数据进行加密,但是从物理上禁止接触才是安全的;
- 带宽消耗,我们需要传输的内容增加了;
- 性能影响,每次 HTTP 请求和响应都带有 Session 数据,Web 服务器在同样的处理下,响应的结果输出越少,支持的并发请求就会越多。
具体情况具体分析,没有绝对的好与不好。
1.3 读写分离
1.3.1 采用数据库作为读库
随着业务的发展,我们的数据量和访问量都在提升,对于大型网站来说,不少业务都是读多写少的,这个状况也会直接反应到数据库上,那么对于这样的情况,我们可以考虑使用读写分离的方式。
我们给系统加上一个读库:
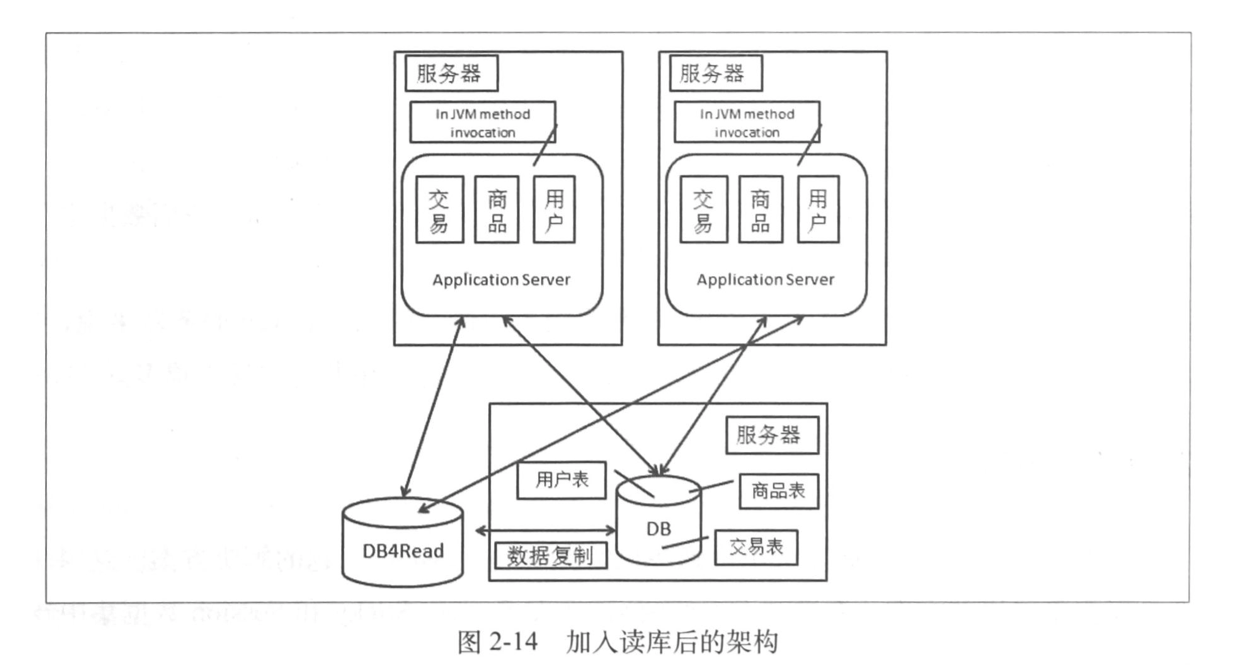
这个架构有两个问题:
- 数据复制问题;
- 应用对于数据源的选择问题。
数据复制延迟带来的就是短期的数据不一致,比如 MySQL 支持 Master + Slave 的结构,提供了数据复制的机制,在 MySQL 5.5 之前的版本支持的都是异步的数据分支,会有延迟,并且是完全镜像方式的复制,保证了备库和主库的数据一致性,而在 MySQL 5.5 中加入了 semi-sync 办同步的支持,它比异步复制要好。主库写入 binlog 之后,会强制此时立即将数据同步到从库,从库将日志写入本地的 relay log 之后,会返回一个 ack 到主库,主库接到至少一个从库的 ack 才认为这条 binlog 写成功。所谓半同步,是说从库将数据拉到 relay log 就算同步成功了。
写操作走主库,读走从库,而事务中的读走主库,所以,不同业务下的选择是有差异的。
1.3.2 搜索引擎其实是一个读库
在搜索的时候,我们可以想到使用数据库的 like 功能,这种实现的代价很大,我们还可以使用搜索引擎的倒排表方式,它大大提升了检索速度,如何对记录进行排序是很重要的。
搜索引擎的功能,首先就是需要根据被搜索的数据来构建索引。随着被搜索的数据的变化,索引也要变化,什么样的数据走搜索,什么样的数据走数据库,其实构建搜索的过程就是一个数据复制的过程。
加入搜索引擎以后系统的结构:
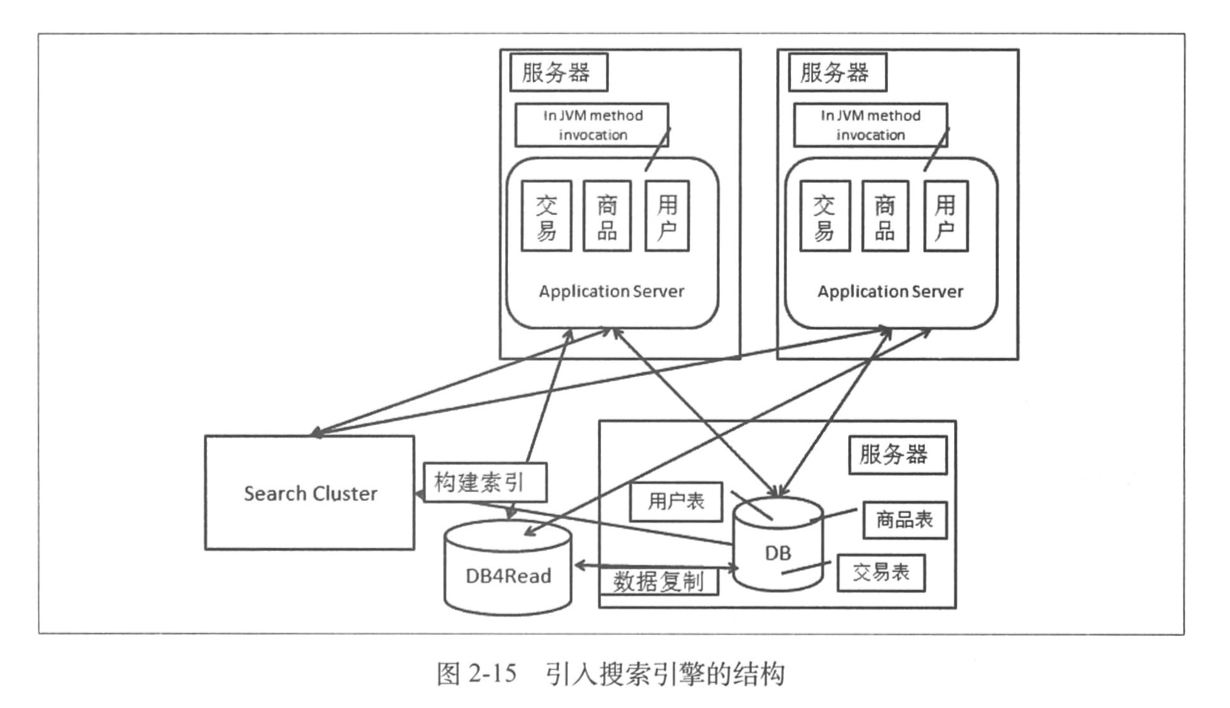
可以看到集群 Search Cluster 的使用方式和读库的使用是一样的,只是「构建索引的过程」基本都是我们自己来实现的,我们从两个维度对搜索系统构建索引的方式进行划分:
- 全量/增量划分;
- 实时/非实时划分。
全量用于第一次建立索引,而增量用于在全量基础上持续更新索引;实时体现在索引更新的时间上,非实时主要考虑对数据源头的保护。
1.3.3 缓存
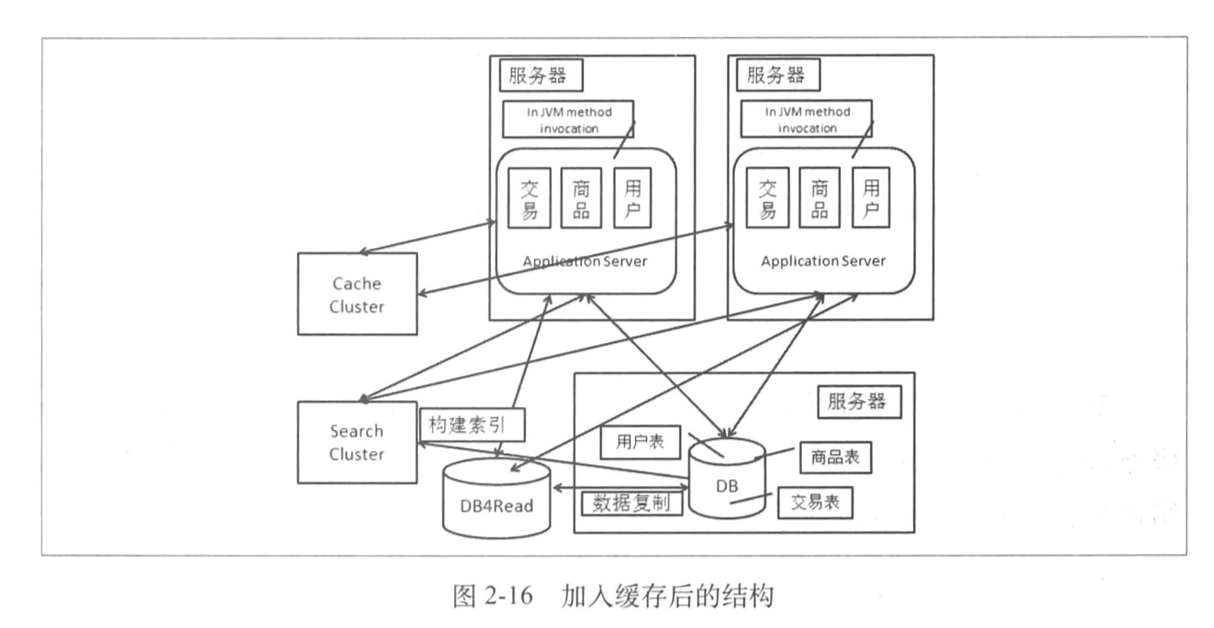
大体上我们将缓存分为:
- 数据缓存:一般在缓存中的数据是 key-value 这样的键值对,而在其中我们放的是热数据;
- 页面缓存:一般「数据缓存」用来加快请求时的数据读取,但最终我们返回给用户的还是页面,有些动态生成的页面或者一部分特别热,我们可以对这些内容进行缓存。
- 以前的方式是使用 Apache 的 ESI 模块,但是这个过程需要对响应结果进行分析,对于不存在内容,会通过 Web 服务器去渲染,再放入缓存中,返回给浏览器;
- 改进后,可以使用比如 JBoss 的 ESI 功能,它在 Web 浏览器中完成渲染和缓存相关的功能,这样更高效,但是没有前一种分工明确。
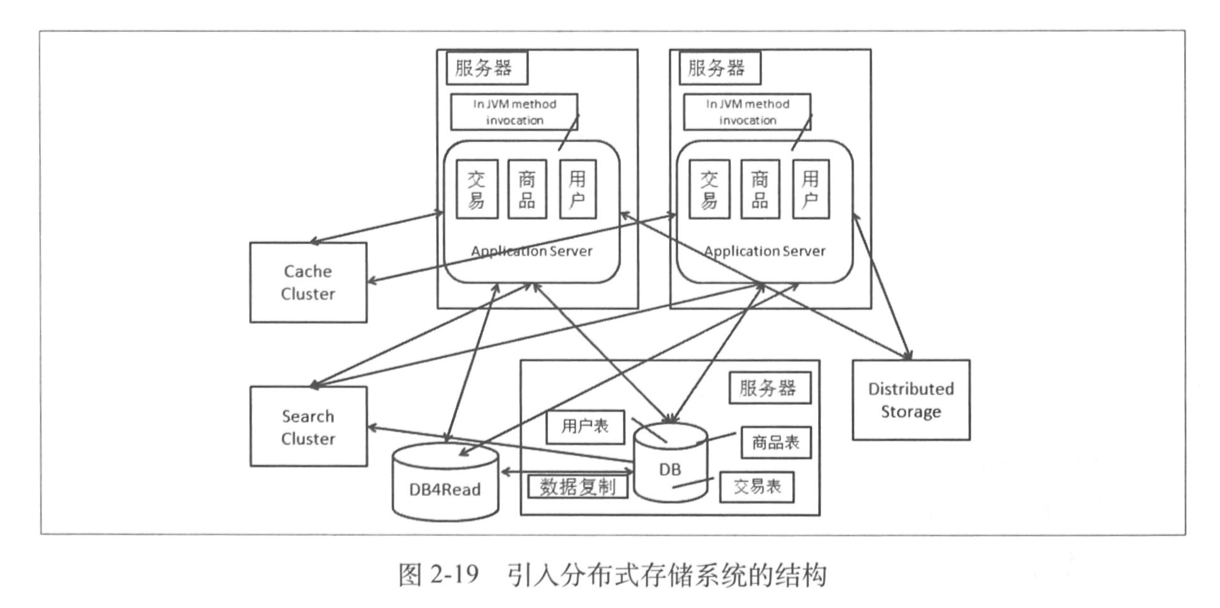
1.4 分布式存储系统
前面,我们把目光集中在数据库,没有错误,因为数据库就是我们性能上遇到的一重大山,但是很多场景下,数据库并不是很合适,也就是分布式存储系统。
分布式存储系统提供一个高容量、高并发、数据冗余容灾的支持,具体有三个常见类:
- 通过分布式文件系统解决小文件和大文件的存储问题;
- 通过分布式 Key-Value 系统提供高性能的半结构化支持;
- 通过分布式数据库提供一个支持大数据、高并发的数据库系统。
现在我们的系统大概长这样:
1.5 读写分离后数据库拆分
随着业务的增加,我们的主库也会遇到瓶颈,现在我们有数据库垂直和水平拆分两种选择。
1.5.1 垂直拆分
换句话说,比如可以把不同业务数据拆分到不同的数据库中,当然,拆法不唯一。
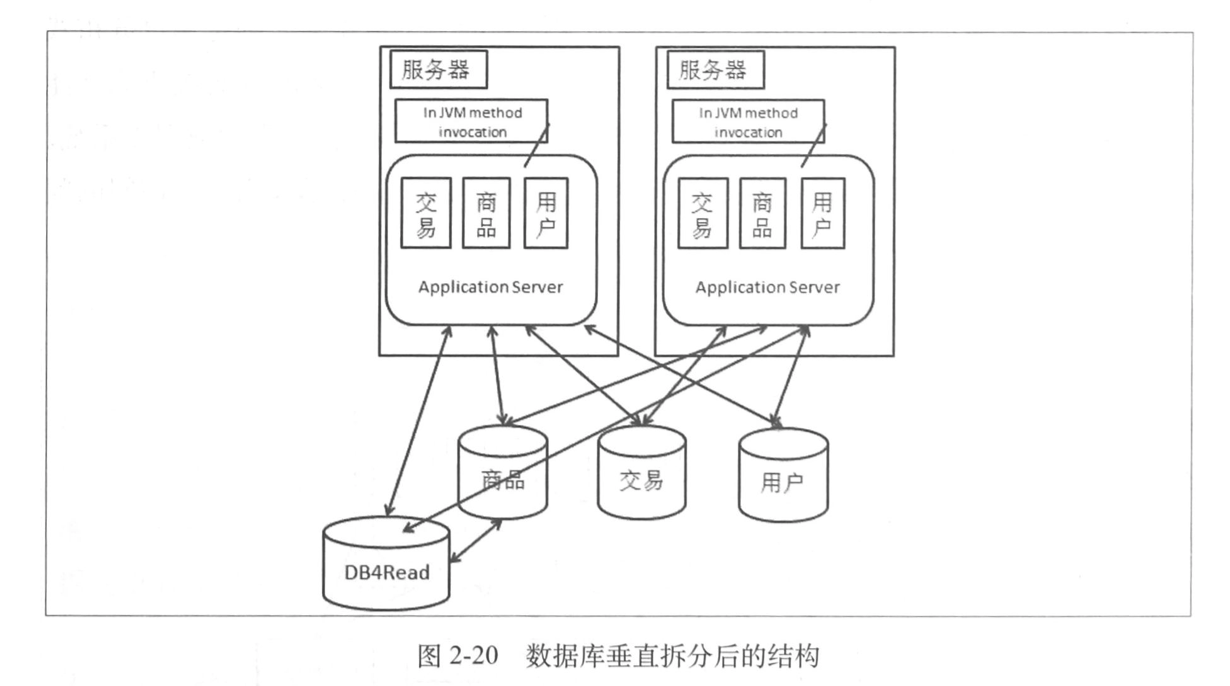
这样做的影响是,我们多了很多数据源是肯定的,每个数据库连接池的隔离,还有跨业务事务处理,两种主流处理方式:
- 分布式事务;
- 去掉事务或者不去追求强事务支持。
垂直拆分解决业务数据都放到一个数据库中的压力问题。
1.5.2 水平拆分
水平拆分就是把一个表的数据拆到两个数据库中,这是因为数据量或者更新量太大。
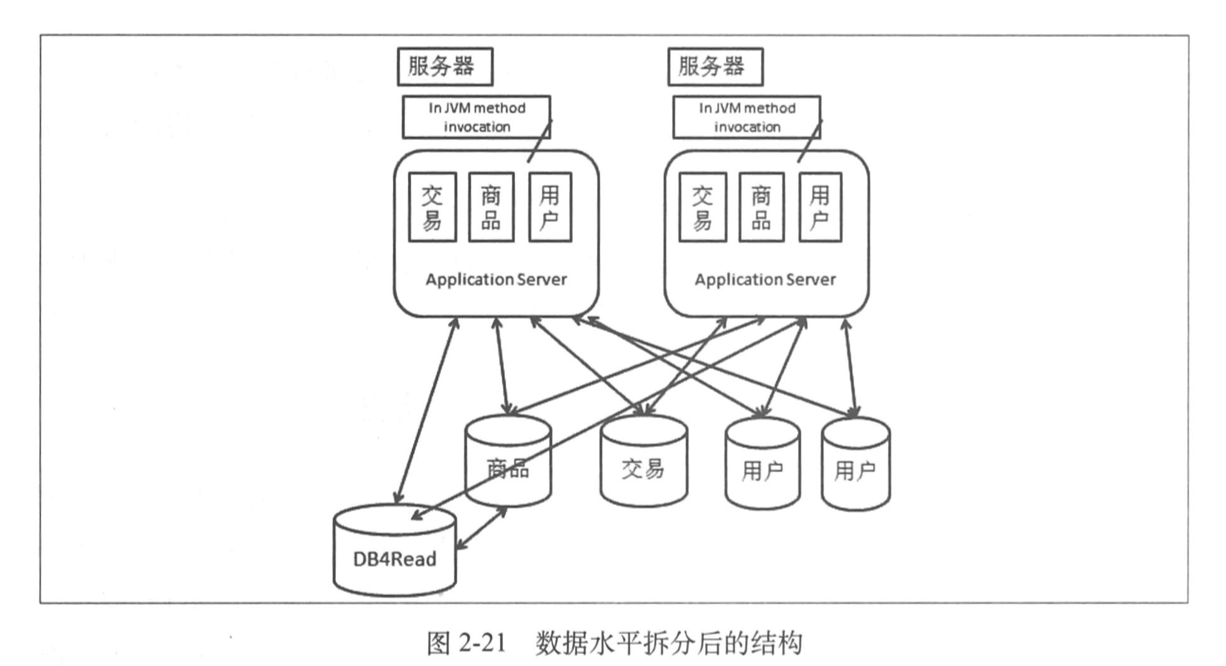
之后要解决这些问题:
- 数据库的路由,现在有两个库了,数据库操作应该了解操作的数据在哪儿。
- 主键处理,原来依赖单个数据库的一些机制需要变化,原来使用的自增字段,现在不能用自增来保证主键不重复了。
- 一些操作需要同时两个表,比如分页操作等。
好处在于一旦完成,我们可以很好应对写入增长的情况。
1.6 数据库问题外的挑战
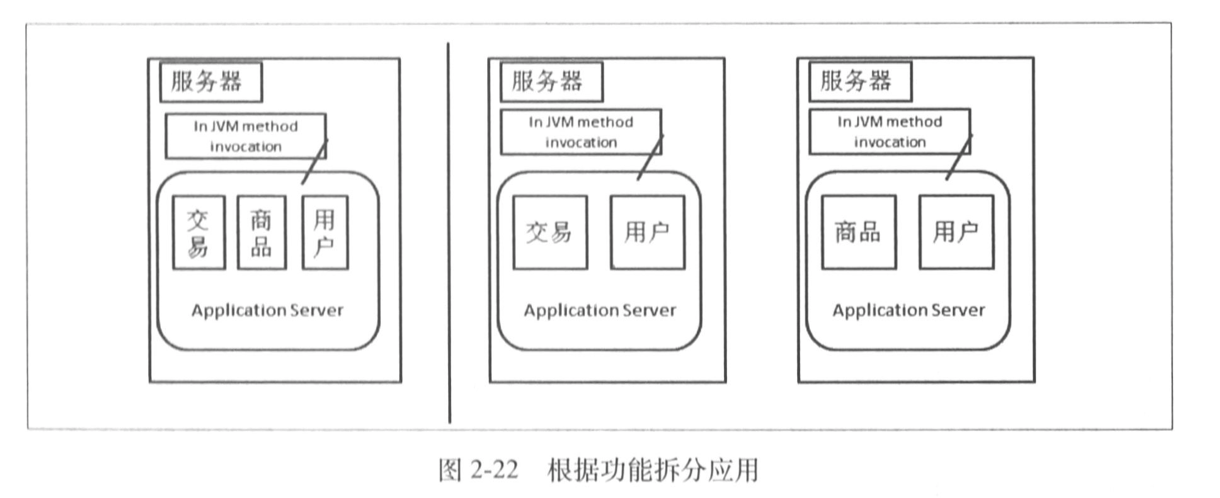
1.6.1 拆分应用
前面我们都在解决数据层面的问题,现在我们要考虑的是不让应用持续变大,需要将应用拆分,从一个应用编程两个或者多个应用。
一个简单的方式是根据应用特性把应用拆分,这样可以把一个大应用变小。并且这些业务应用之间不存在直接调用,它们都依赖底层的数据库、缓存、文件系统、搜索等。
1.6.2 走向服务化
这是一个服务化系统结构的简图:
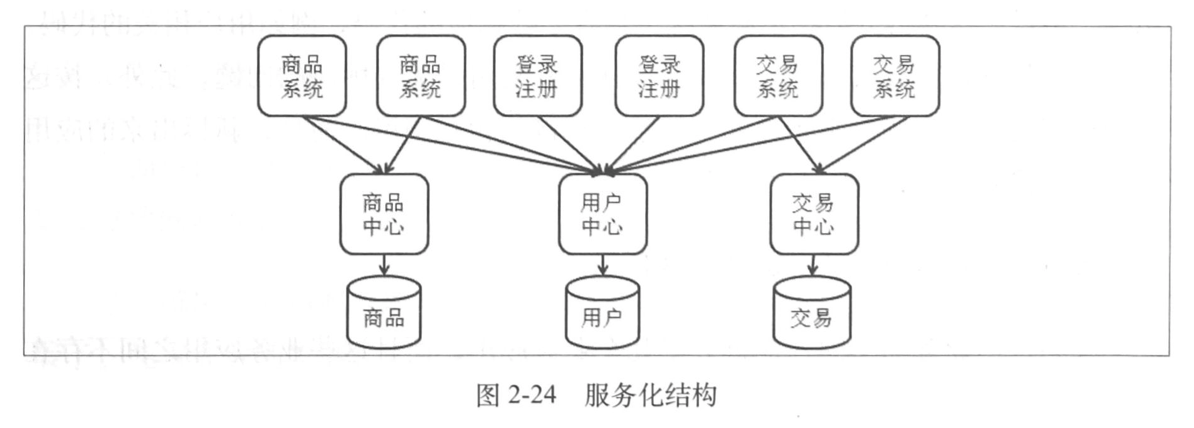
顶层 Web 系统,中间服务中心,底层数据库。
各个服务中心可能不在一个机器上,当然其他 Web 系统或者数据库可能也不在一个机器上,所以主要通过远程调用的形式交互,连接数据库的事情交给了数据库,更好控制系统本身的发展。
1.7 消息中间件
Message-oriented middleware MOM 消息中间件,它是在分布式系统中完成消息的发送和接收的基础软件。
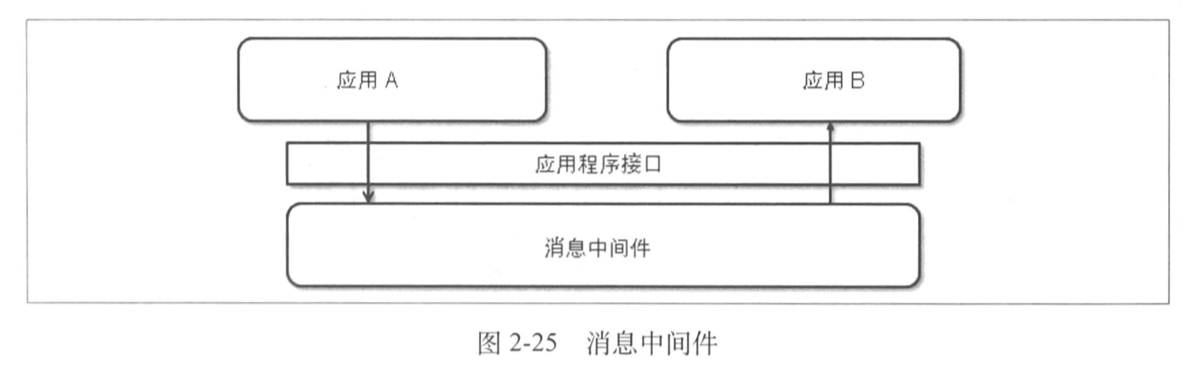
它最大的两个好处:异步、解耦。应用 A 和应用 B 都和消息中间件打交道,而这两个应用并不会直接联系。