数据层的挑战与应对
这一节主要讲数据库的设计,首先要说的就是单机设计方式,一个 JVM 连上一个 DB 完成。
1. 垂直/水平拆分的苦难
除了上升硬件能力以外,我们有什么办法给数据库减压,这里提了三个方法:
- 优化应用,减少不必要的数据库压力;
- 引入缓存、加入搜索引擎支持;
- 分摊 DB 压力,分库分表。
这一节当然从分库分表开始,垂直拆分是把同一个数据库里不同业务的数据分到不同的数据库里;水平拆分则是根据规则把同一业务的数据拆分到不同数据库里。
垂直拆分影响:
- 单机 ACID 保障打破,原来的事务处理收到影响,引入分布式事务;
- Join 可能变得复杂,因为数据被分到了不同的库里,需要使用应用或其他方式解决;
- 外键约束场景也会相应收到影响。
水平拆分影响:
- ACID 打破;
- Join 影响;
- 外键影响;
- 生成 ID 策略收到影响;
- 现在单表查询跨库。
2. 事务处理
现在我们就来细聊多库以后事务的支持问题。
2.1 分布式事务模型与规范
X/Open 组织提出的分布式事务规范——XA。我们先把 XA 当黑盒,先来看看 DTP (X/Open Distributed Transaction Processing Reference Model)模型。其中包含三个组件:Application Program、Resource Manager 和 Transaction Manager 。
- AP 即应用程序,它定义了事务的边界;
- RM 资源管理器,即一个 DBMS 系统,或者一个消息服务器管理系统,AP 通过 RM 对资源进行管理,资源实现 XA 实现的接口;
- TM 事务管理器,负责协调和管理事务,给事务指定标识,监控他们的进程,其标识即事务分支标识 XID ,由 TM 指定。
如图可以看到三者的通信关系。
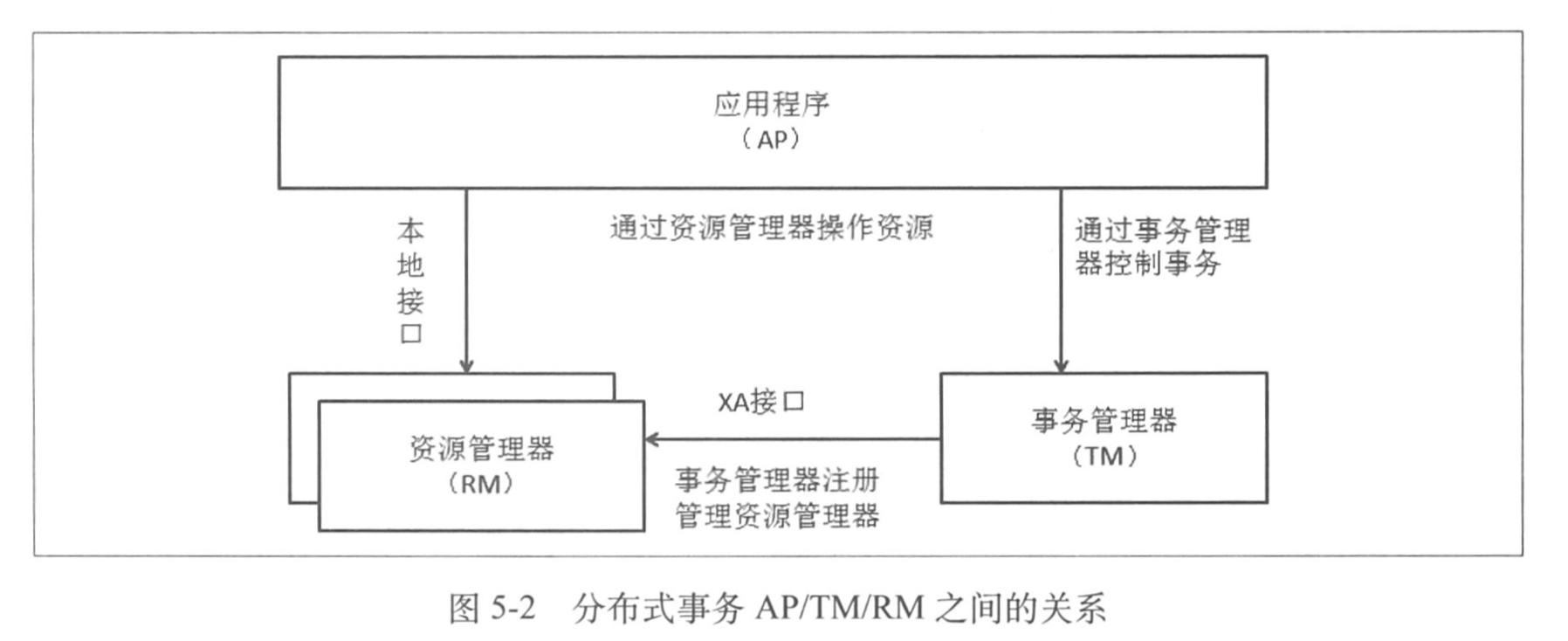
AP 与 RM 是一定要存在的,而 TM 则是人为加入的,因为我们需要给多台机器达到一致的状态,因此需要这个单点来进行调节。
此外,DTP 中还有几个概念:
- 事务:一个完整工作的单元;
- 全局事务:一次操作多个 RM 的事务叫做全局事务;
- 分支事务:全局事务中,每一个 RM 所对应任务的集合就是分支事务;
- 控制线程:事务上下文环境,用来关联 AP RM TM 三者。
下图是完整的 DTP 模型。
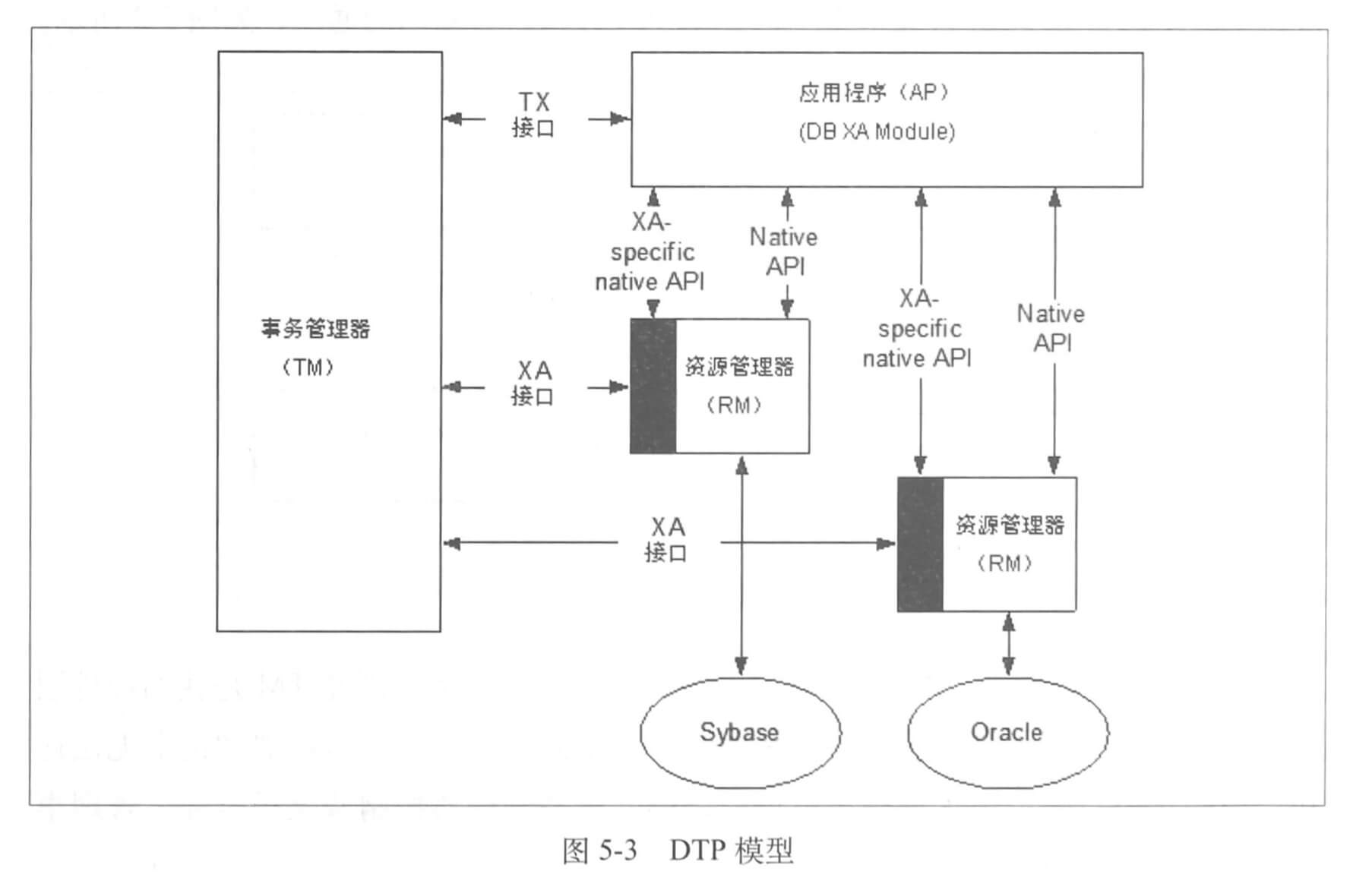
上图重点在于 AP RM TM 三者之间的关系。
- AP 与 RM 之间:使用 RM 自身提供的 native API ,当开始分布式事务的时候,AP 需要得到 RM 的连接,此连接由 TM 管理,然后使用 XA specific native API 交互;
- AP 与 TM 之间:图中为 TX 接口,也是 X/Open 规范的。主要用于控制事务,比如启动、提交、回滚;
- TM 与 RM 之间:通过 XA 接口进行交互,TM 管理了 RM 的连接。
2.2 二阶段提交
2PC ,Two Phase Commitment Protocol ,二阶段是对于单库事务提交来说的。单库中我们 DB 完成后「提交」或「回滚」,而这里我们增加了一步——「准备」,因此称作二阶段。
顾名思义,二阶段就有两个阶段,我们这里假设存在两个「资源」需要进行同步的操作,可以看到如下两个阶段。
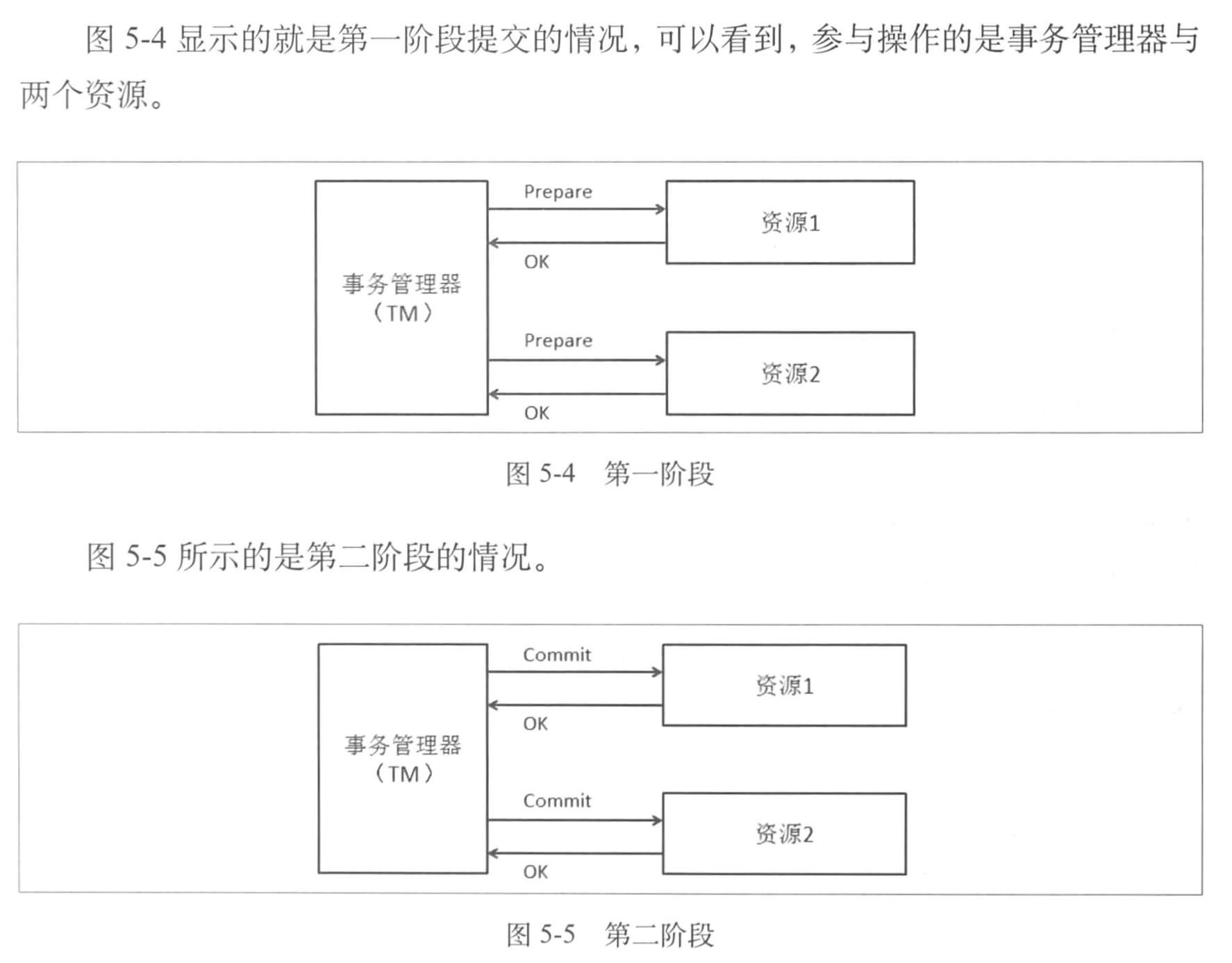
可以发现主要的参与者仅有 TM 与两个资源对象,值得注意的是,如果在「准备」阶段有一个资源准备失败了,那么二阶段的处理就是回滚所有的资源。
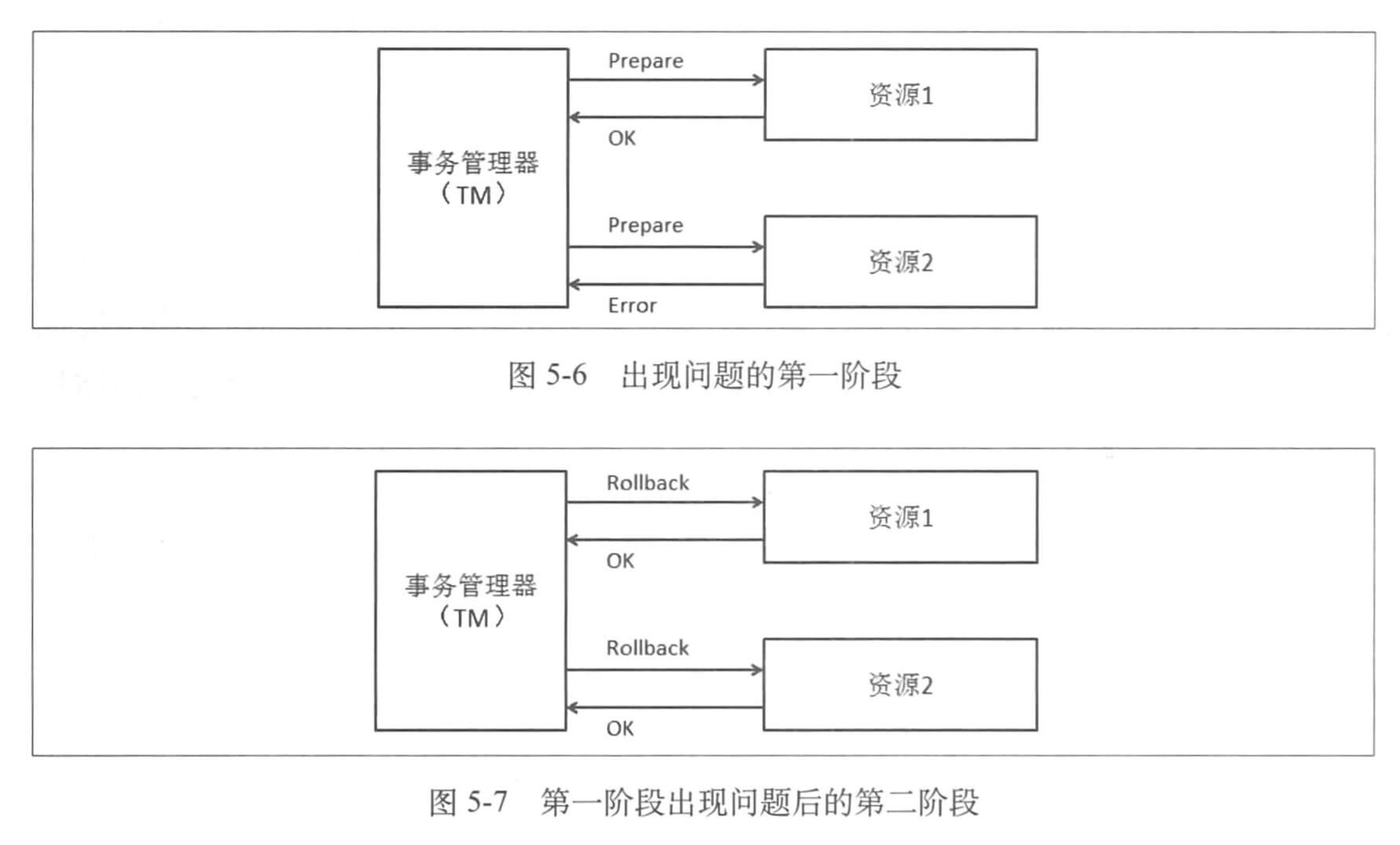
网络上交互的增加以及引入 TM 的开销,是使用 2PC 事务开销大的两个重要方面。
2.3 CAP/BASE
CAP 理论相当经典:
- Consistency: all nodes see the same data at the same time. 所有节点同时看到相同的数据;
- Availability: a guarantee that every request receives a response about whether it was successful or failed. 保证成功还是失败,只能二选一;
- Partition-Tolerance: the system continues to operate despite arbitrary message loss or failure of part of the system. 即使系统有部分问题或消息丢失,但是系统依然可以运行,即分区容忍。
我们只能同时选择三者的其中两者。
- CA,放弃分区容忍,加强了一致性和可用性。这是传统单机的做法;
- AP,放弃一致性,追求分区容忍和可用性。这是很多分布式系统的选择,例如很多 NoSQL 就是如此;
- CP,放弃可用性,追求一致性和分区容忍性。这种选择可用性比较低,主要问题在于网络导致系统不可用。
主流方案是 AP ,并不是不关心 C ,而是在 AP 满足的基础上再考虑 C 。
再来看看 BASE 模型:
- Basically Available:基本可用,允许分区失败;
- Soft state:软状态,接收一段时间的状态不可用;
- Eventually consistent:最终一直,保证最终数据状态一致。
可以发现选择了 AP 以后和 BASE 模型是相通的。
2.4 Paxos 协议
它把二阶段要轻量一些,节点之间的交互有两种方式:
- 共享内存共用一份数据;
- 消息传递信息。
消息在传递过程中容易出现失败,而 Paxos 就是帮助解决「一致性问题」的一个方案。
Paxos 的前提是不存在「拜占庭将军问题」。也就是说需要保证当前是一个可信的通信环境,消息都是准确的。
我们假设有三种角色的节点,Proposers Acceptors Learners :
- Proposers,提议者,提出议案的角色;
- Acceptors,接收者,收到议案后进行判断的角色,可以选择「接收」,若议案被大部分接收者「接收」,则议案会被「批准」即 Chosen ;
- Learners,学习者,只能学习被「批准」的议案的角色。
每个角色可以身兼数职。
这里有两个重要的名词:
- Proposal,议案,由 Proposers 提出,被 Acceptors 「批准」或「否决」;
- Value,决议,每个决议都有是一由二元组
{编号,决议}组成。
Paxos 在解决的问题用上面这些名词来描述的话,就是:
- Value 只有被 Proposers 提出后才能被 Chosen(未 Chosen 的决议叫做 Proposal );
- 在 Paxos 的执行过程中,一次只能 Chosen 一个 Value;
- Learners 只能获得被 Chosen 的 Value 。
每个角色都会进行记录,记录中 Proposal 不会被改变,而有些信息可以改变:
- LastTried[p],由角色 p 试图发起的最后一个 Proposal 的编号,初始值为 -∞ ;
- PreviousVote[p],角色 p 投票的所有 Proposal 中,编号最大的 Proposal 对应的投票,初始值为 -∞ ;
- NextBallot[p],角色 p 发出所有 LastVote(b,v) 消息中,Proposal 编号 b 的最大值。
那么 Paxos 的流程就可以这样理解:
- 角色 p 选择一个比 LastTried[p] 大的 Proposal 编号 b ,设置 LastTried[p] 为 b ,然后将 NextBallot(b) 发送给其他角色;
- 在 p 收到一个 b > NextBallot[q] 的 NextBallot(b) 消息后,角色 q 将 NextBallot[q] 设置成 b ,然后发出一条 LastVote(b,v),其中 v = PreviousVote[q] ;
这里比较绕的点是 p 收到 q 的消息,且这条消息的 NextBallot 要比 b 小,如果说 NextBallot[q] <= b ,则忽略。
- 然后奇妙的事情发生了,当一个集合 Q 的所有人都收到一个 LastVote(b,v) 后,角色 p 就会发起一个「编号为 b ,人数为 Q ,Proposal 为 d 」的表决,然后 p 给这个 Q 里每一个人都发送一个 BeginBallot(b,d) 的消息;
- 在收到一个 b = NextBallot[q] 的 BeginBallot(b,d) 的消息后,人员 q 在编号为 b 的 Proposal 中投票,设置 PreviousVote[q] 为这一票,然后向 p 发送了 Voted(b,q) 消息;
- p 收到了 Q 中每一个 q 的 Voted(b,q) 后(此时 LastTried[p]==b),将 Proposal d 的记录记下,发送 Success(d) 给每一个 q ;
- 每一个人收到 Success(d) 后,将 Proposal d 记下。
如果一个系统中同时有人提案,可能会出现碰撞失败,然后双方都需要增加议案的编号再进行提交;如果此时提交仍然可能出现冲突,因此双方需要继续增加编号。这就产生了「活锁」,且永远没有尽头。
解决方法是整个集群里只有一个 Leader ,所有的 Proposal 都由他提出,而 Leader 出现了问题就需要重新选举。
2.5 集群内数据一致性
这里讲的是亚马逊 Dynamo 的论文中 Quorum 和 Vector Clock 算法的比较详情。
首先是关于 Quorum 算法,它用来权衡分布式系统中数据一致性与可用性,其中有是三个变量:
- N:数据复制节点数
- R:成功读操作的最小节点数
- W:成功写操作的最小节点数
如果 W+R>N ,是可以保证强一致性的,而如果 W+R≤N ,则是可以保证最终一致性的。
根据 CAP 理论,举个例子,如果使 N=W ,而 R=1 ,则可用性会大大降低,但是一致性是最好的。
而 Vector Clock 的思路是对同一份数据的每一次修改都加上 <修改者,版本号> 的二元组,在现实生活中我们往往不能在一群中达到一个一致结果,在计算机这样的虚拟世界里这样的问题尤为重要,而「时间」是 Vector Clock 算法的核心,所有结果都带上时间。
假设现在有四个人:Alice Ben Catby Dave 。Alice 说周三聚餐,Dave 和 Catby 商量改周四,Dave 又和 Ben 商量改周二,最后 Alice 汇总大家的结果。
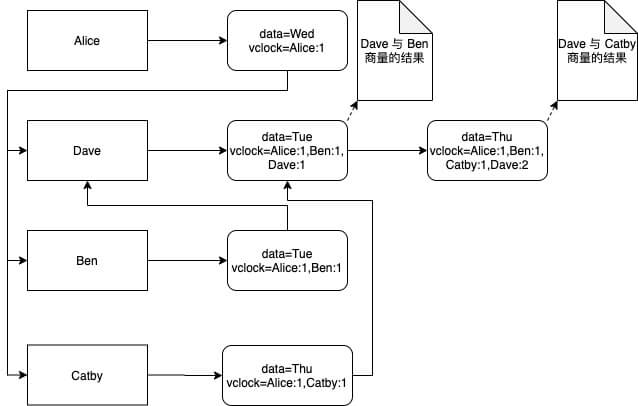
现在 Alice 收到来自 Ben 的消息是周四,收到来自 Catby 的消息同样是周四(这里有一个选择,Dave 第二次的决定是周二还是周四,这里假设是 Dave 第二次依然决定是周四,没有同意改成周二),答案就有解了。
3. 多机 Sequence 问题
水平分库以后,单表放在多机上,自然自增 id 不能用了,连续 id 有两个特性:
- 唯一性
- 连续性
从唯一性可以想到简单的 UUID ,或者根据 IP MAC 时间 机器等生成一个唯一的 id ,但是连续性并不好。
有一种较为主流的实现方式是把所有 id 在一个地方进行管理,这里有几个关键问题。
- 性能问题:每次远程获取 id 都有资源消耗,一种方式是一次取一批 id ,然后缓存在本地,但是如果此时宕机,那么这些 id 就浪费了;
- 稳定性问题:id 生成器其稳定性要靠整个集群来保证;
- 存储问题:底层存储的选择空间很大,根据不同的类型进行容灾方案。
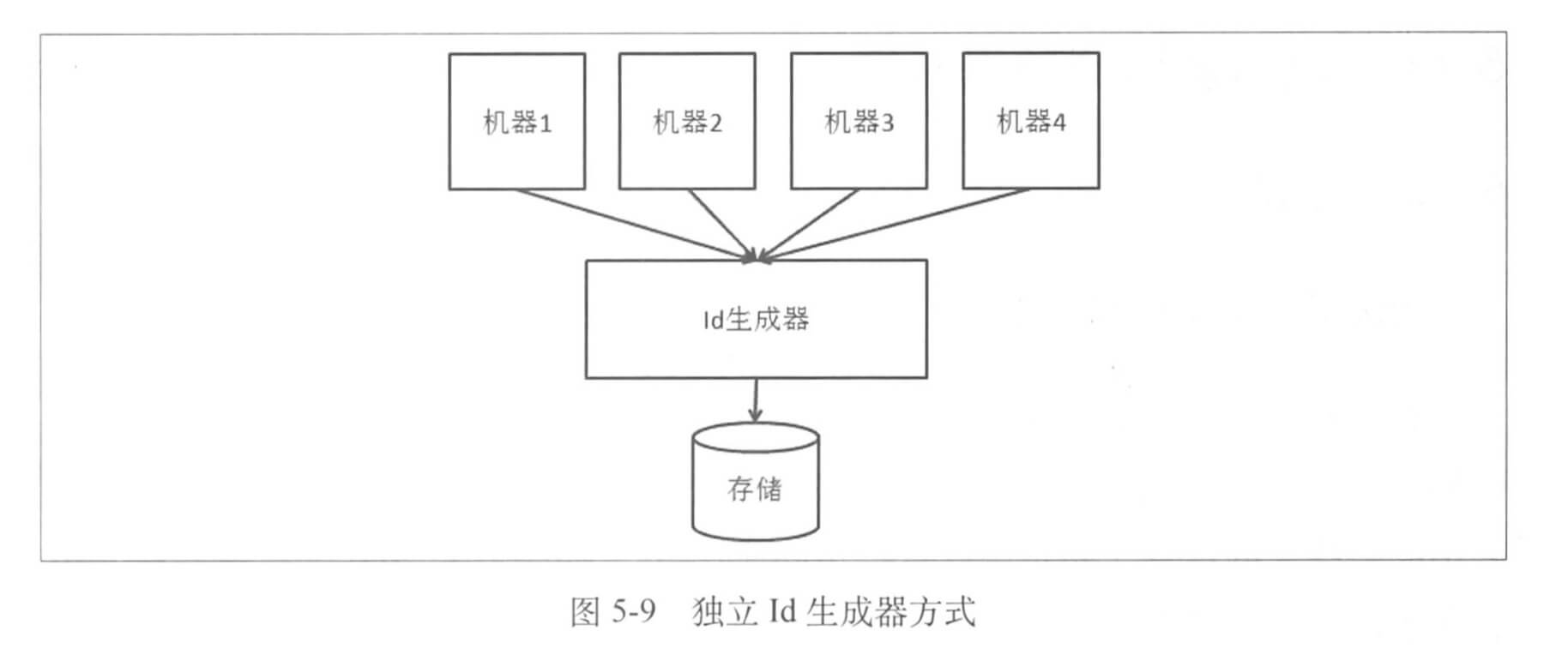
下面有两种存储方案,一种是在底层使用一个独立的存储来记录每个 id 序列当前的最大值,并控制并发更新:
另一种则是直接把整个 id 生成器舍弃,把相关逻辑放到需要生成 id 的应用本身:
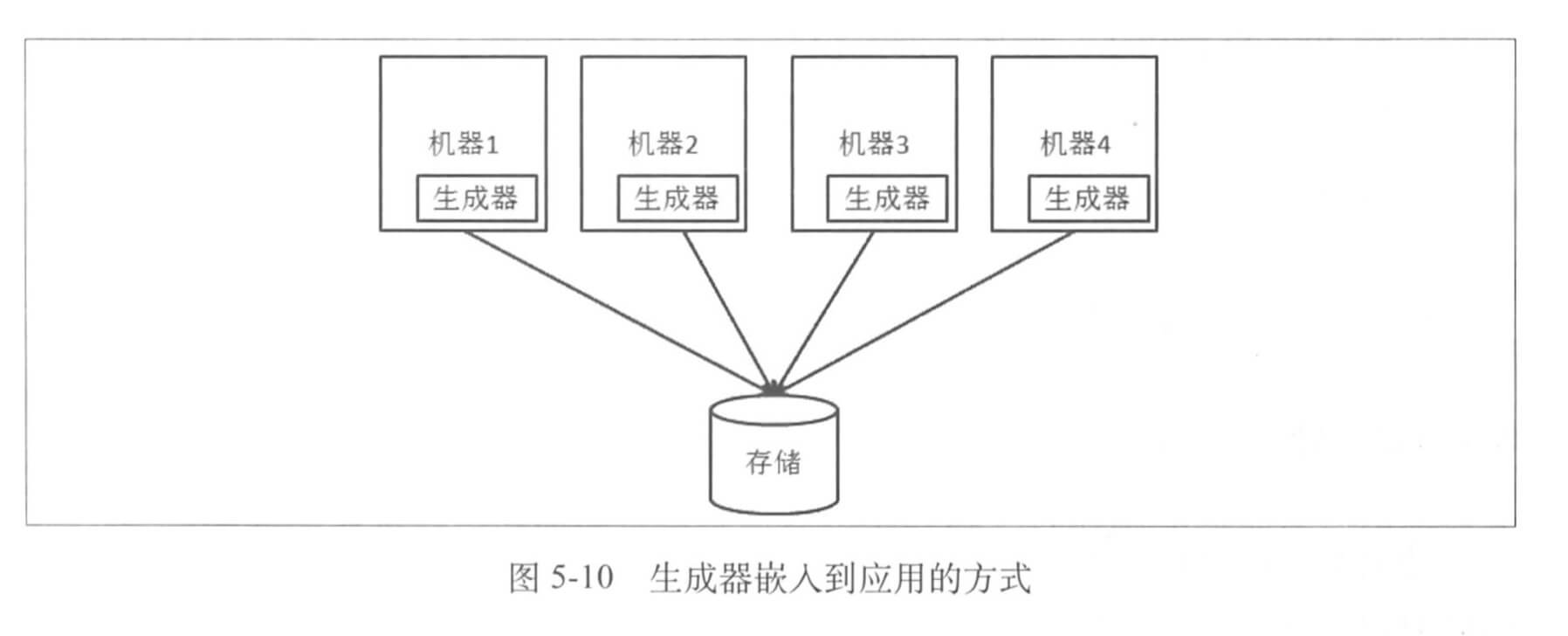
但是因为没有中心节点,我们还是希望生成器之间有通信,管理上也需要额外的功能。
4. 多机查询
分库以后,存在问题解决了,读的问题仍然存在,我们还是要把数据从不同机器 join 到一个库里,解决记录有如下几种。
- 在应用层把原来的数据库的 join 操作分成多次的数据库操作,说白了就是原来的 join 不用了,用逻辑来连接;
- 数据冗余,把一些常用数据冗余,去除 join 操作;
- 借助外部系统比如搜索引擎来解决跨库问题。
假设用户信息根据地域进行划分,一个数据库分成多个库,而库中有多个表,如图。
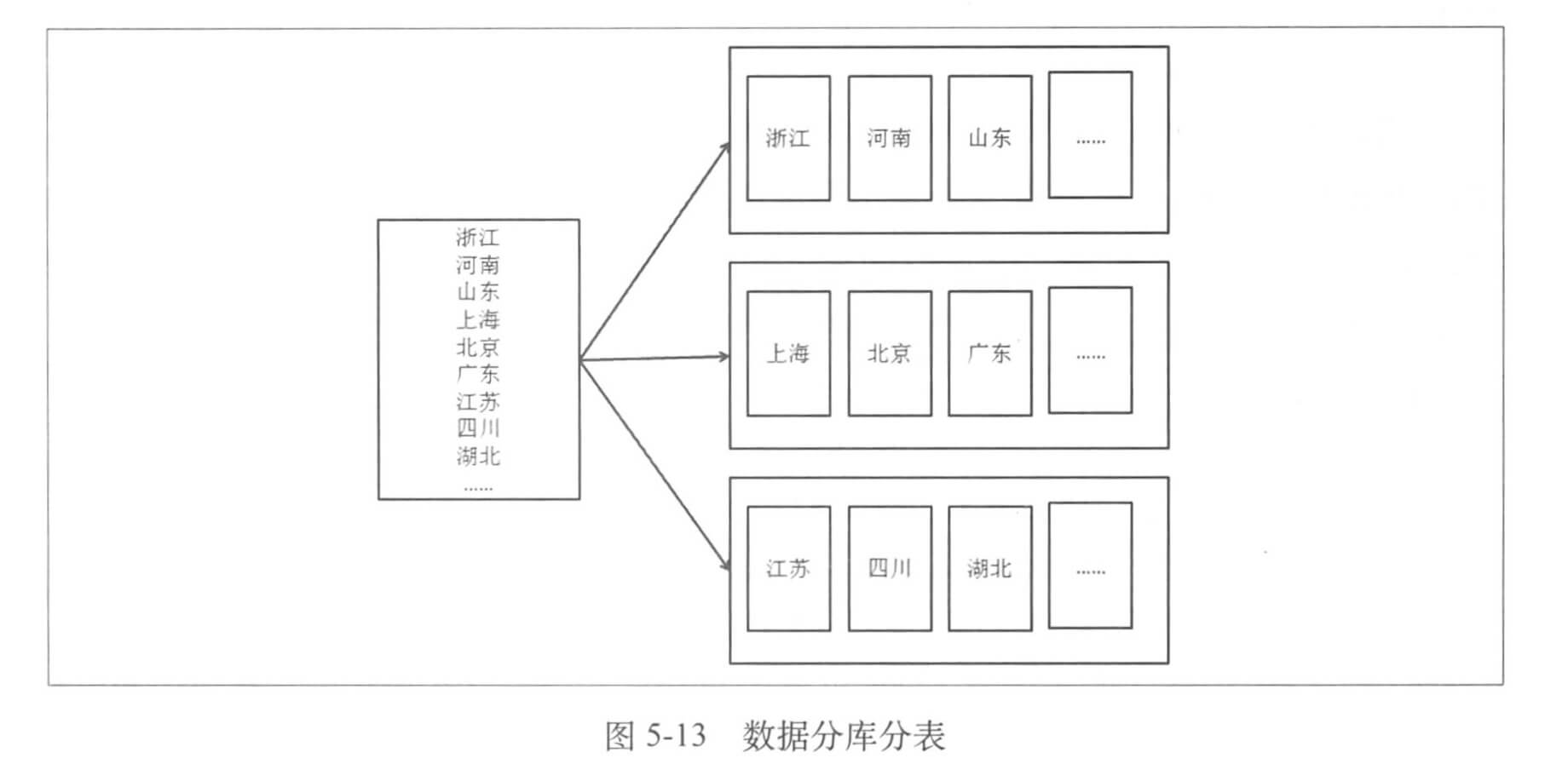
我们在查询的时候可能会遇到跨库、跨表的问题,结果处理还是相对简单,但是有写场景需要特殊处理:
- 排序:如果各自有序应该用多路归并,如果各自无序则全排;
- 函数处理:使用 Max Min Sum Count 等对多个数据来源的值进行相应函数处理;
- 求平均值:这没啥好说的其实,多个数据源的 Sum 求和计算平均即可;
- 非排序分页:看属于「同等步长的分页」还是「同等比例的分页」,前者是说同页中来自不同数据源的记录数相同;后者是说同页中来自不同数据源的数据占数据总数的比例是一样的;
- 排序后分页:这个最复杂,需要把排序和分页放在一起的情况,我们需要每个数据源结果都排好序,然后在取下一页的时候每个数据源都给出足量的数据进行排序,约到后面负担越大,比如第100页,需要每个数据源把前100页都取出进行归并,才能得到正确的结果。