从领域知识剖析 Netty
1. Netty 下三种 I/O
- 阻塞与非阻塞:要不要死等,阻塞会等待直到有数据;非阻塞会直接返回。
- 同步与异步:数据就绪后谁来操作,自己去读是同步;主动回调是异步。
BIO——阻塞同步;NIO——非阻塞同步;AIO——非阻塞异步。
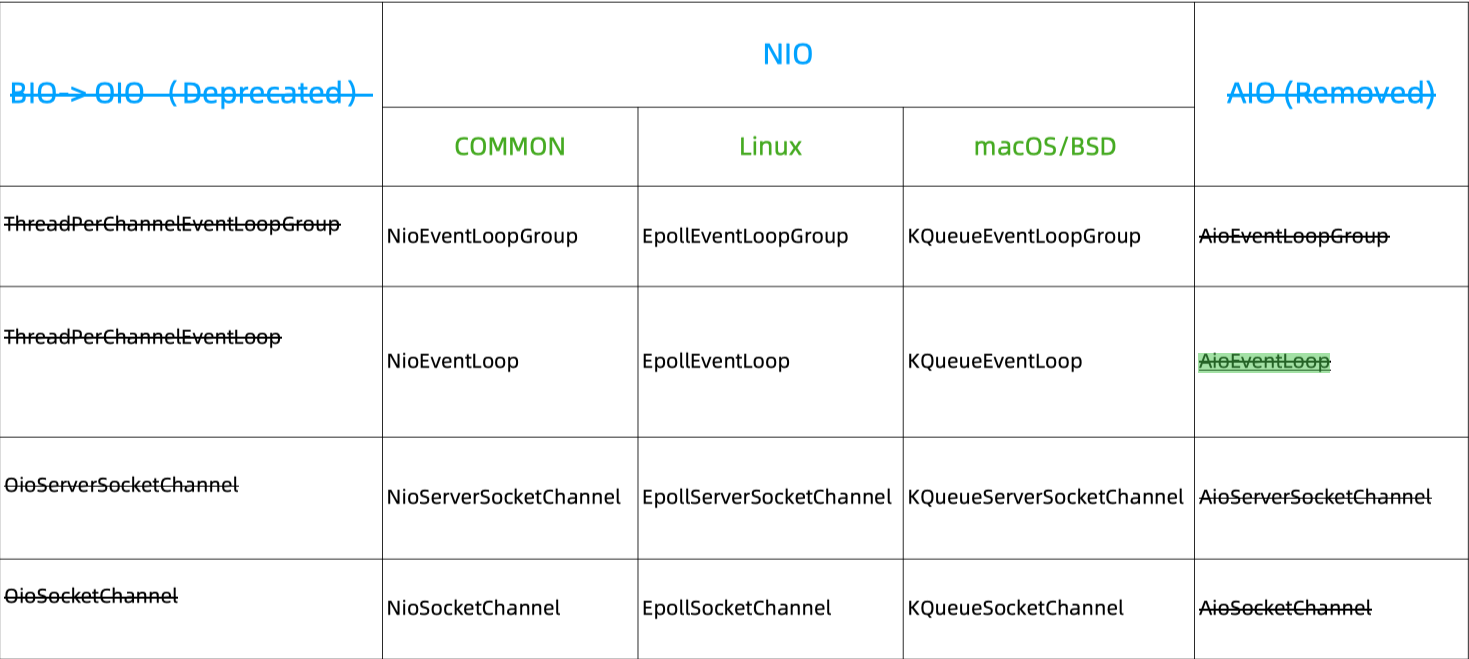
Netty 对三者都有过支持,阻塞导致资源占用多因此不用,而 AIO 的弃用是因为 Linux 下 AIO 相较于 NIO 性能提升不明显,效益不够高,同时 Linux 下 AIO 的实现不够完善。
BIO 在连接数少,并发不高的情况下性能不输于 NIO ,所以我们应该结合具体场景进行分析。
2. Netty 如何切换 I/O 模式?
我们需要换 EventLoopGroup (开发模式)与 Channel (I/O 模式)即可,
Channel 通过泛型+反射+工厂实现 I/O 模式的切换,可以跟进源码看到 ReflectiveChannelFactory 的实现,它作为一个工厂方法会生产通过传入的 class 进行 Channel 的反射实例化。这里 Netty 的 Channel 会帮助我们创建 socketChannel 。
而 EventLoopGroup 是一种开发模式,这也是 Netty 标语中『事件驱动』的意义,也就是 Reactor 模式的实现。
3. Netty 对 Reactor 的支持
- Reactor 单线程——一个人包揽所有工作;
- Reactor 多线程——多个人做所有事情;
- Reactor 主从——一个或多个人专门做某些事情。
对于 BIO 是 Thead-Per-Connection 模式,对于 NIO 是 Reactor 模式,对于 AIO 是 Proactor 模式。
对于 Reactor 而言,核心流程:
- 注册感兴趣的事件;
- 扫描是否有感兴趣的事件发生;
- 事件发生后做出相应的处理。

3.1 Thread-Per-Connection 模式
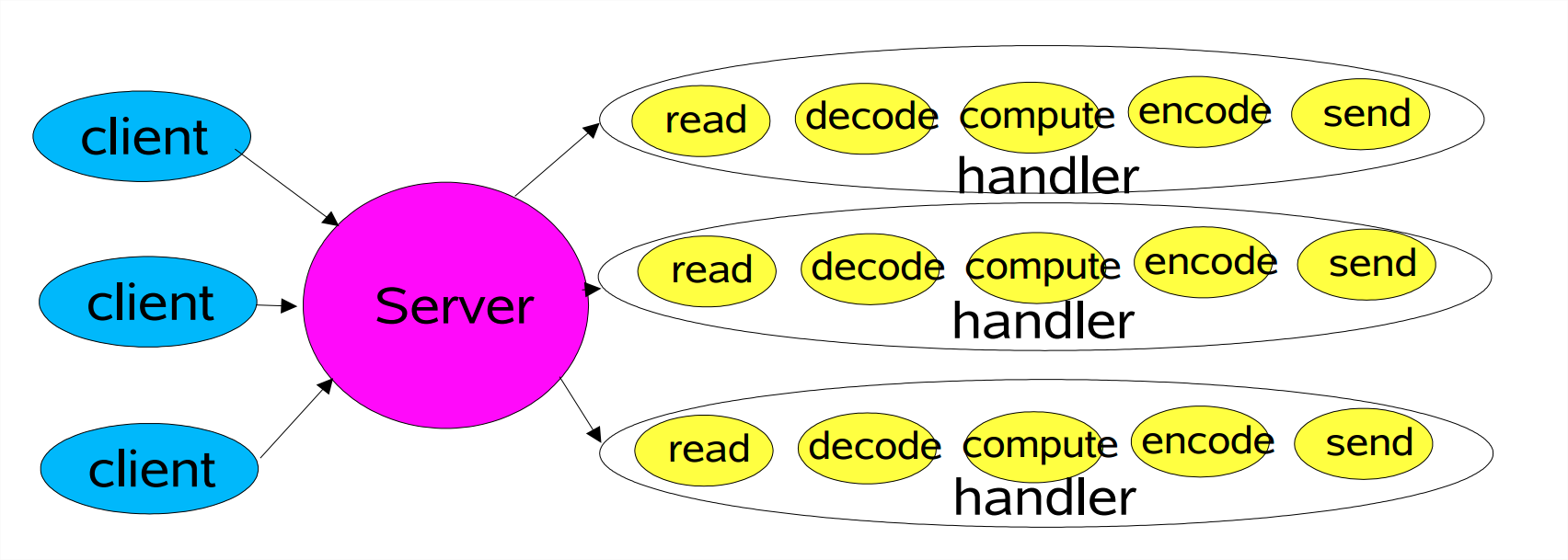
线程池可以解决这个问题吗?仅仅解决线程无限增多的问题,事实上我们还增加了等待线程的阻塞,下面是对应代码。

值得注意的是上文的 read 和 write 都是阻塞操作。
3.2 Reactor 单线程
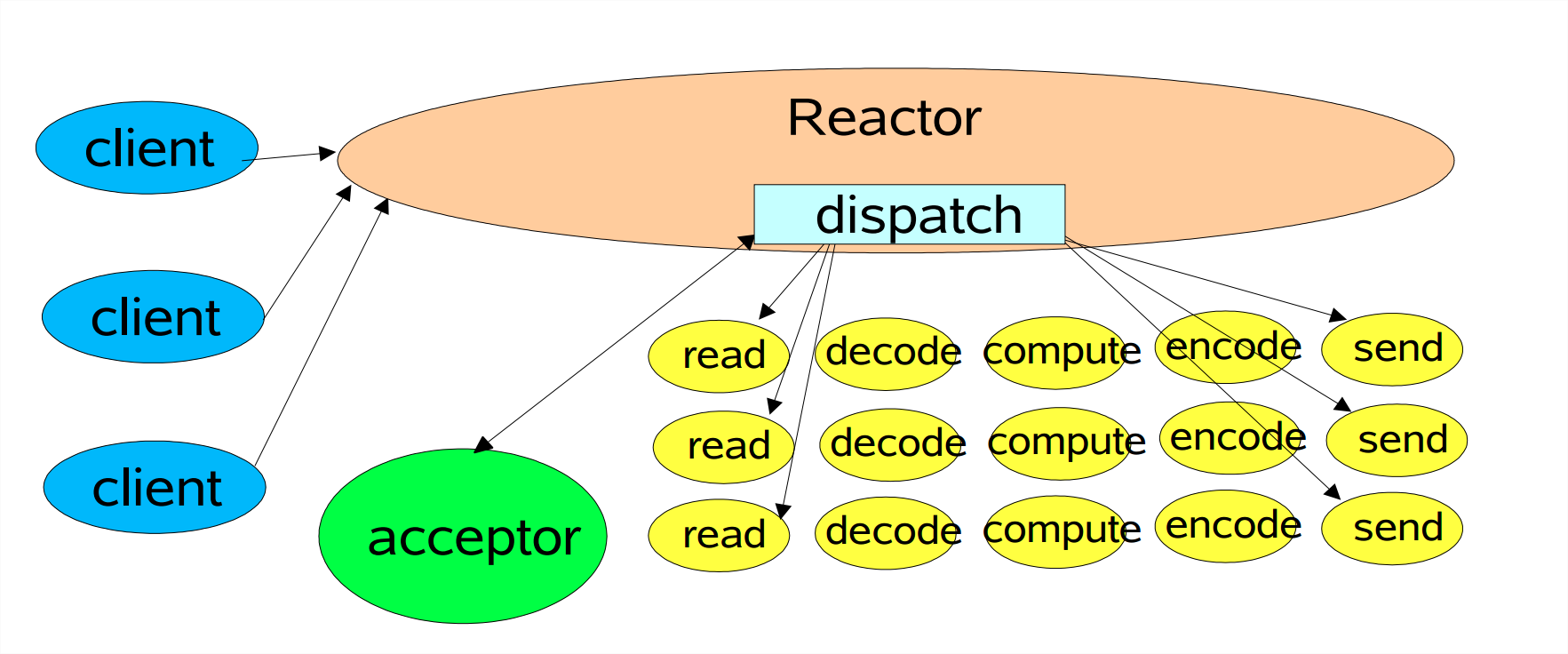
所有一切都是一个线程在做,如果线程挂了自然就都挂了。
3.3 Reactor 多线程
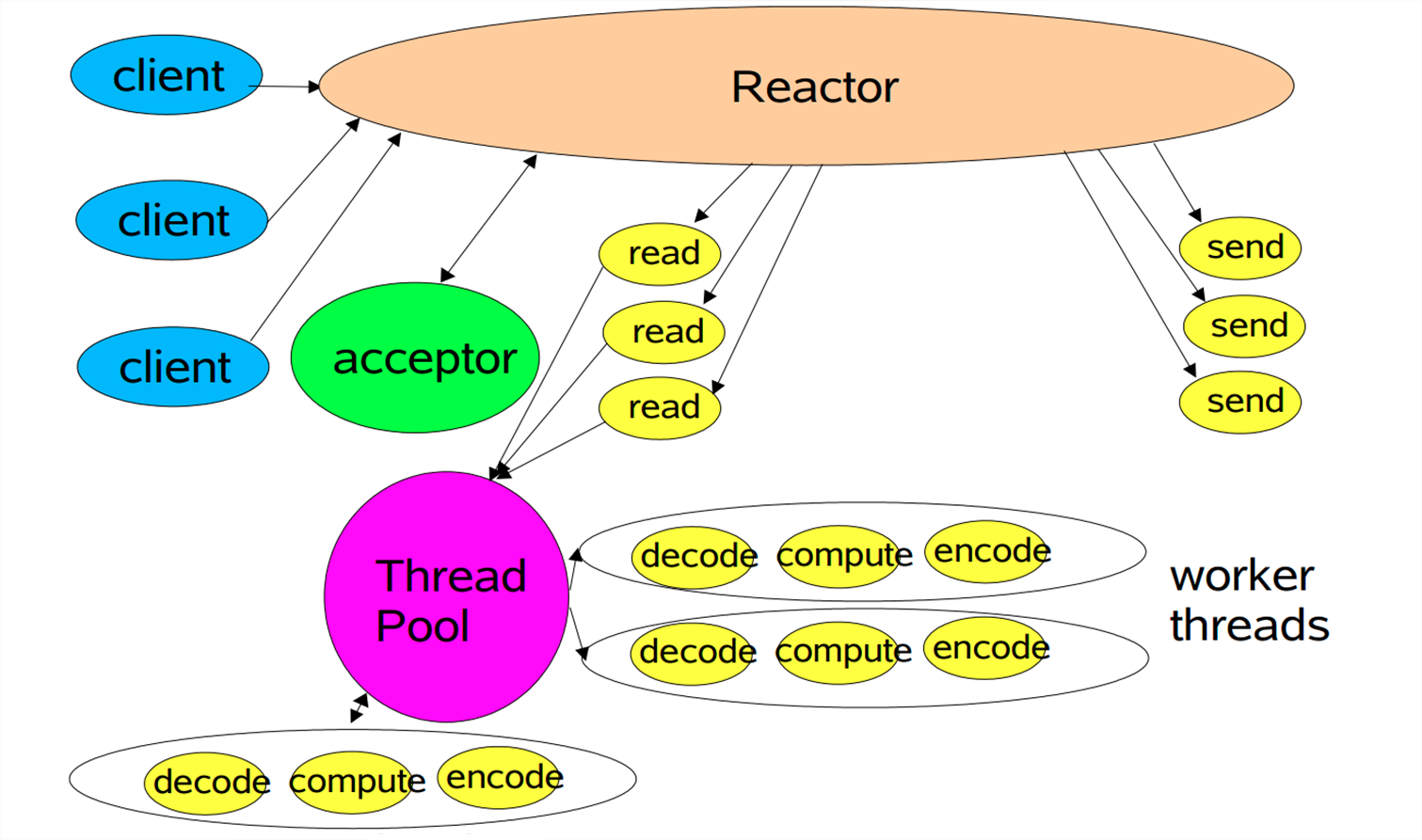
它在单线程的基础上把 decode compute encode 这些操作放到一个单独的线程池中操作。
3.4 Reactor 主从
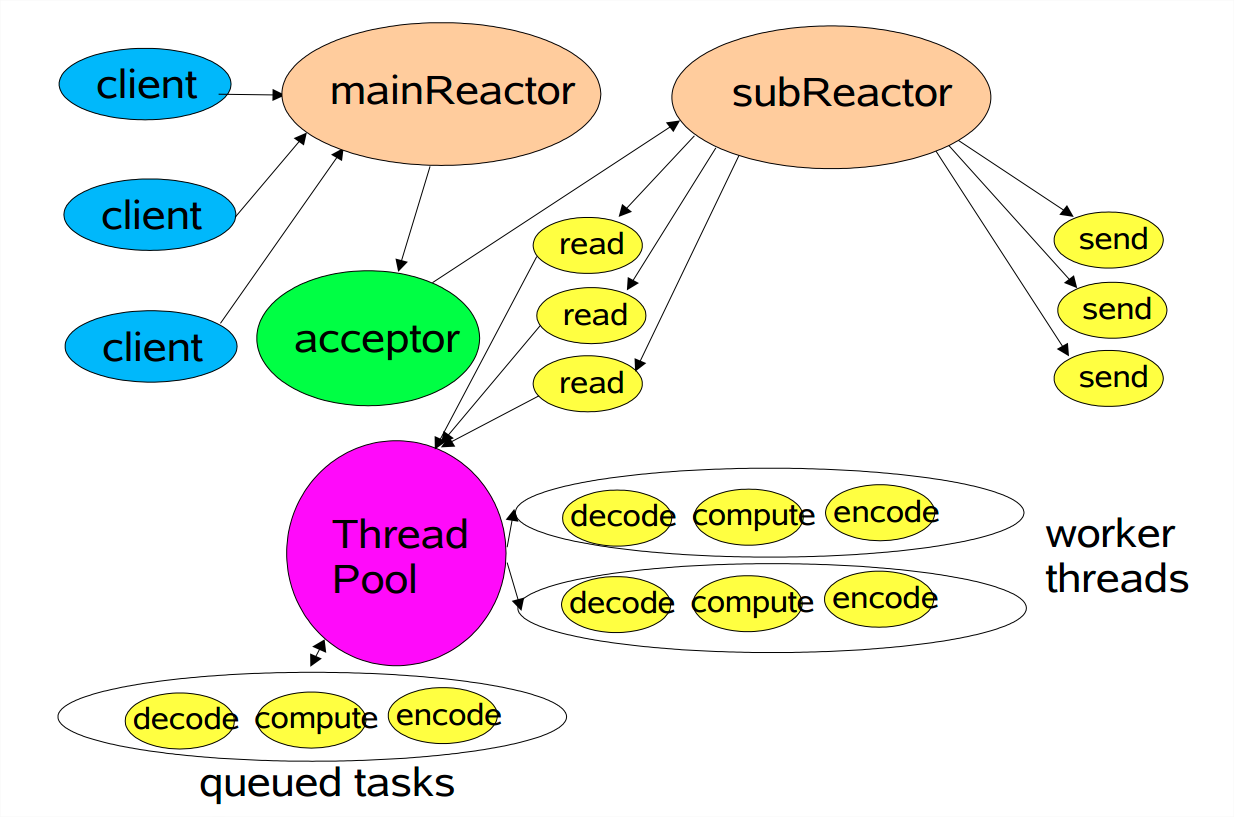
它把接收连接和具体操作进一步分离,让专业的人做专业的事。
3.5 以主从为例
3.5.1 如何实现 Reactor 模式?
这里要注意一下,Netty 代码量非常大,我们通过 Usage of xxx 和 Hierarchy caller 先找调用处再看调用层次,非常有效。
可以从代码里发现两种 channel (ServerSocketChannel 和 SocketChannel)绑定到两种 group (parentGroup 和 childGroup)中,这就完成了一个主从 Reactor 的支持。
3.5.2 为什么说的 Netty main reactor 大多都不能用到一个线程组?
通过调用栈可以发现,Netty 的 group 方法被 doBind 方法调用,它的作用是绑定地址和端口,对于一个服务器而言我们一般绑定一个地址和一个端口,也因此我们只会在一个 group 中绑定到一个子元素。
3.5.3 Netty 给 Channel 分配 NIO event loop 的规则是什么?
从 ServerBootstrap 类的 channelRead 方法可以找到一个 register 调用,它是对 EventLoopGroup 接口的调用,也就是这个问题的答案了。这个 register 方法有两个实现,进到 MultithreadEventLoopGroup 的实现中,发现 next().register(channel) 这样的代码,显然这是一个调用链,跟进 next() 找到 chooser.next() ,这里有一个选择器,它的 next 方法有两种,一种是 GenericEventExecutorChooser 另一种是 PowerOfTwoEventExecutorChooser ,找到了。
- 对于一个数组而言,第一种方式
generic采用的是——递增、取模、取正值的方式; - 第二种则要求数组长度为 2 的幂次,它会用
&进行操作,运算效率更高,但需要数组长度符合要求。
3.5.4 Netty 如何跨平台?
比如在 NioEventLoopGroup 类里有一个构造器,使用了 SelectorProvider.provider() 方法,有一句 provider = sun.nio.ch.DefaultSelectorProvider.create() 这里的 create 方法是跨平台的,在 mac 下实现是返回一个 KQueueSelectorProvider ,在 win 下返回的是 WindowsSelectorProvider ,这是 JDK 的不同返回的不同实现。
4. TCP 粘包、半包 Netty 处理
比如我们发 ABC DEF 收到的就不一定是原样,收到如果是 ABCDEF 就是粘包,收到如果是 AB CD EF 则是半包现象。
粘包原因:
- 发送方写入数据 < 套接字缓冲区大小;
- 对方读取数据不够及时。
半包原因:
- 发送方写如数据 > 套接字缓冲区大小;
- 发送的数据大于 MTU ,必须拆包。
传输原因:
- 一个发送可能被多次接收,多个发送可能被一次接收;
- 一个发送可能占用多个传输包,多个发送可能共用一个传输包。
真正的原因则是——TCP 是一个流式协议,消息无边界。
UDP 则是有界限的,所以没有粘包和半包的现象。
所以解决之本就是找到消息的边界。
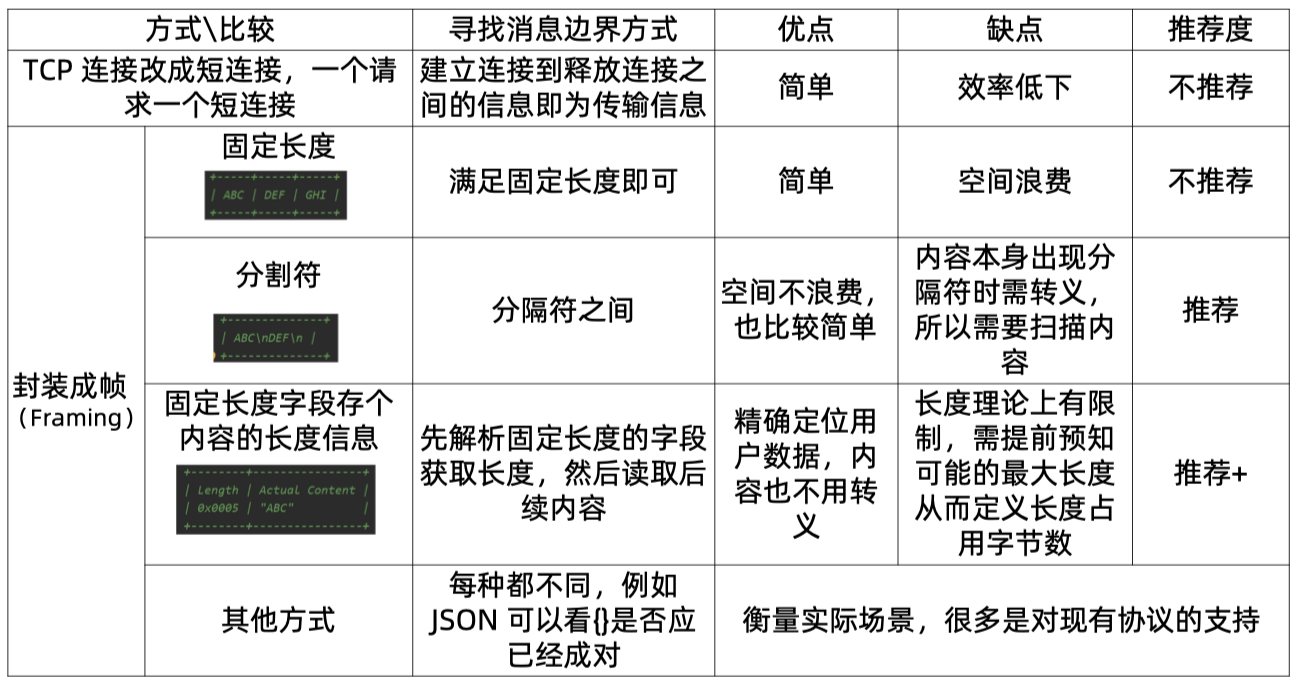
Netty 在封装成帧的实现上有如下支持。

这三个解码类都继承自 ByteToMessageDecoder ,这个类就是用来解决粘包和半包问题的。解码入口在 channelRead 方法,这里有一个参数 cumulation 这是一个数据积累器,其后它就是方法参数中的 ByteBuf 对象,代码会走到 decode 这是一个模板方法,以 FixedLengthFrameDecoder 为例,当 cumulation 的数据长度满足 frameLegnth 的时候就会解析,多出来的数据还会保留,我们就这样解决了粘包和半包问题。
说回 cumulation 的累加,它有两种方式,一种是内存复制,按需扩容;另一种方式是组合,它不是内存复制,而是一种视图。内存复制的是默认的使用,因为累加器最后还是服务于 decode 的行为,行为不同可能会因为内存复制与非内存复制的方式产生实现误差,因此选用更为通用的内存复制的方式。
这里看一下 LengthFieldBasedFrameDecoder ,其文档非常强大。
1 | /** |
5. 二次编解码
第一次解码是解决半包、粘包时的解码,这里我们得到了字节;接着我们还需要一层解码用来进行对象转换,也就是所谓的二次解码。
- 一次解码:
ByteToMessageDecoderByteBuf 的转换 - 二次解码:
MessageToMessageDecoder将 ByteBuf 转换成 Java Object
这样做是为了分层、降耦合。Java 序列化、Marshaling、XML、JSON、MessagePack、Protobuf、其他…二次解码非常多。
JSON、MessagePack、Protobuf 在时间和空间上较优;
可读性 JSON > MessagePack;
- 最流行的是 Protobuf ,是一个灵活、高效的序列化数据的协议,但是它的可读性比较差。
在 netty-codec 子工程下可以找到大量的编解码类。
同时,Netty 下有一个世界时钟的例子,它是使用 Protobuf 进行二次编解码的。
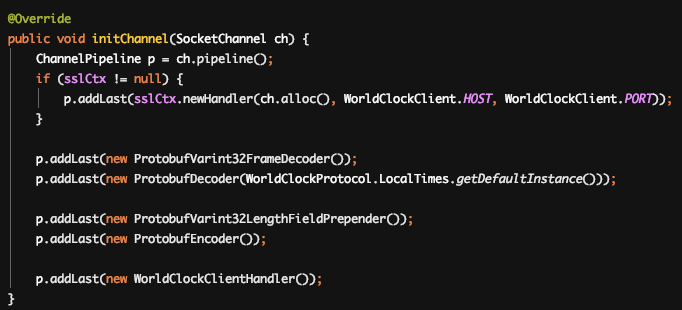
这里有 5 个 add 的内容,分别是一次编解码,二次编解码,执行内容。执行的顺序应该是一次解码、二次解码、执行、二次编码、一次编码。
6. keepalive 与 Idle 监测
6.1 什么是 keepalive ?
keepalive 就是一次 request 期望得到 response 。TCP 的 keepalive 有这样几个参数:
- net.ipv4.tcp_keepalive_time = 7200
- net.ipv4.tcp_keepalive_intvl = 75
- net.ipv4.tcp_keepalive_probes = 9
通过的7200秒后发送 keepalive 消息,当探测没有确认时, 按75秒的重试频率重发,一直发 9 个探测包都没有确认,就认定 连接失效。所以总耗时一般为:2 小时 11 分钟 (7200 秒 + 75 秒* 9 次)。
6.2 为什么还需要应用层 keepalive ?
传输层 TCP 的 keepalive 是判断是否『通路』,应用层的 keepalive 是用来判断服务是否存在;TCP 的 keepalive 是默认关闭的;TCP 的 keepalive 时间太长了。
HTTP 的 keepalive 和这个不是一回事,它特指『长连接』。
6.3 什么是 Idle 检测?
Idle 检测仅仅负责诊断,而后做出不同行为,下面是两种 Idle 检测的使用方式。
- 配合 keepalive :当有数据传输时,不发送 keepalive,当没有数据传输时,先发 Idle 再发 keepalive ;
- 直接关闭连接:简单粗暴。
6.4 Netty 中的 keepalive 如何生效
在 ServerBootStrap 里有一个 childOption 方法,这里的 child 就是客户端使用的含义,把设置的值配置到 child 的 Channel 中,一路向下可以找到 setOption 方法,它有两种方式设置 keepalive 之类的参数:
- 一种是通过配置
NioSocketChannel它的实现是通过 Java NIO 的 api 来进行配置; - 另外一种是通过
DefaultSocketChannelConfig的实现,堆砌 if else 代码。
6.5 Netty 中的 Idle 如何生效
Idle 对于 Netty 是一个扩展能力在 handler/timeout 下,被分为 read / write / all 三种。
对于写而言,具有写意图和写成功是两回事,比如写了但是缓存满了,或者没有写了但是没有写完。
这三种 Idle 的实现都是线程中执行的,是一种监控行为。
ReadTimeoutHandler 是由 ReadTimeoutIdle 触发的,但是 WriteTimeoutHandler 不是由 WriteTimeoutIdle 触发的,这是一个 Netty 的坑,前者是用来判断 read 空闲的,后者是判断 write 是否完成。
7. Netty 锁事
同步三要素:原子、可见、有序。
如果我们需要一个原子 Long ,应该会最先想到使用 AtomicLong ,但是在 Netty 中使用了另外一种方式,它使用 volatile long ,同时定义一个 AtomicLongFieldUpdater ,这么做的好处就是节省空间,
1 | private static final AtomicLongFieldUpdater<ChannelOutboundBuffer> TOTAL_PENDING_SIZE_UPDATER = AtomicLongFieldUpdater.newUpdater(ChannelOutboundBuffer.class, "totalPendingSize"); |
volatile long 占用 8 byte ;而 AtomicLong 则是 8(volatile long) + 16(对象头) + 8 (引用) 共 32 byte ,当然也有指针压缩、对齐之类的技术,最后可能比 32 大也有可能比 32 小,但总归是大了 3 倍以上。
当 JDK >=8 时会尽量使用 LongAdder ,其效率高于 AtomicLong ,底层是一个 base 域和一个 cells 数组(保存计数值),低并发(没有竞争/ CAS 不失败)直接修改 base ,高并发更新到 cells 数组,分离出热点更新,如果要获取真正的long值,只要将各个槽中的变量值与 base 累加返回。
此外还有比如针对 JDK8 前的 ConcurrentHashMapV8 这样的实现(现在已经不用了),还有针对多写单读使用 MpscChunkedArrayQueue 而不是使用 LinkedBlockingQueue 。
Netty 中大量使用局部串行,也就是 Channel 中的 I/O 请求都是 Pipeline 的方式执行,而同时它又是整体并行的方式:
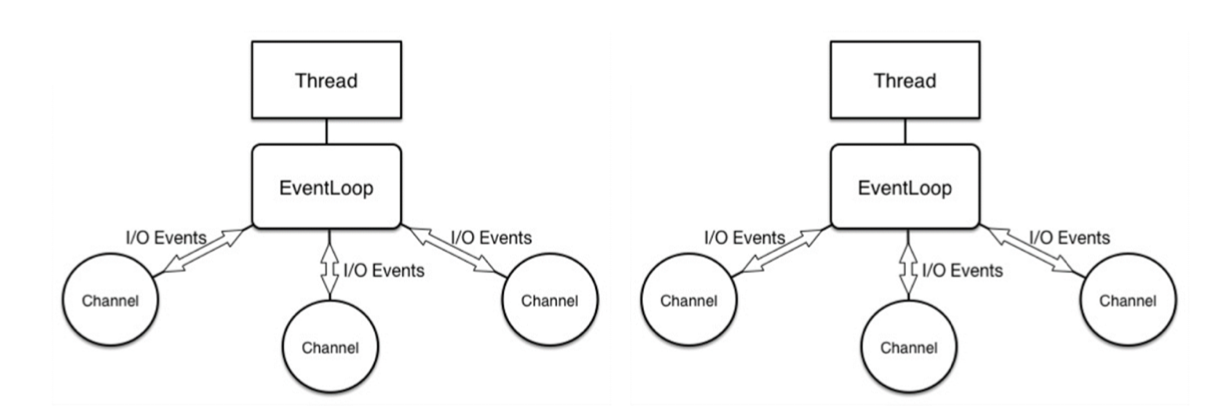
这里一个 EventLoop 服务于多个 Channel ,同时每一个 Channel 中都是局部串行:
最后在 Netty 中能不用锁就不用锁,比如 ThreadLocal ,来避免资源争用,Netty 中实现了一个轻量级的 ThreadLocal 即 FastThreadLocal 。
8. Netty 的内存使用
目标:
- 占用内存少;
- 应用速度快。
Netty 的实现方式:
- 能用基本类型就不用包装类型;
- 能定义成类变量就不要定义成实例变量;(实例越多,浪费越多)
- AtomicLong -> volatile long + static AtomicLongFieldUpdater ,减少对象本身大小;
- 对分配内存进行预估,比如
HashMap提前给预估大小; - Zero-Copy ,使用逻辑组合来替代实际的复制;使用包装来代替实际复制;调用 JDK 的 Zero-Copy 接口,比如使用 NIO 的
FileChannel.transferTo()方法; - 堆外内存,堆——heap,非堆——non heap,堆外——off heap。堆外更大减轻了 GC 压力,但是速度慢,而且收 OS 管理风险更大;
- 内存池,开源可以用 Apache Commons Pool ,Netty 有一个自己的内存池
io.netty.util.Recycler。
Netty 源码中内存的使用:
- Netty 默认使用了池化的实现,
io.netty.allocator.type默认值是pooled;- 在
PooledDirectBuf类下,可以找到PooledDirectByteBuf buf = RECYCLER.get()这里就是从对象池中获取了一个对象,本质上是通过 stack 的pop获取一个,没有再新建; - 再在调用
PooledByteBuf.deallocate()的时候使用recycle()归还对象,还到 stack 中。
- 在
- Netty 切换堆内和堆外内存;
- 参数设置,
io.netty.noPreferDirect = true可以使用堆外内存; - 类
PooledByByteBufAllocator的构造方法写true,可以同样进行切换。
- 参数设置,
- 本质上,Netty 通过
ByteBuffer.allocateDirect(initialCapacity)方法可以调用 JDK 的方法来分配堆外内存。